






















Im vorherigen Artikel, "Zwei Möglichkeiten zur Fehlerbehandlung mit SAP BW und SQLScript", haben wir die verschiedenen Szenarien der Fehlerbehandlung auf SAP BW on HANA und BW/4HANA vorgestellt. In diesem Beitrag beleuchten wir das erste Szenario ausführlich.
Dabei werden die Mechanismen des DTP Errorhandlers genutzt. Die fehlerhaften Sätze werden in den Fehler-Stack geschrieben, wo sie anschließend manuell korrigiert werden können. In der SQLScript Transformation werden die fehlerhaften Datensätze in die Tabelle errorTab geschrieben. Um mit dieser Tabelle auf einem BW/4HANA System arbeiten zu können, müssen Sie in der Transformation die Einstellung Fehlerbehebung für HANA-Routinen zulassen aktivieren.
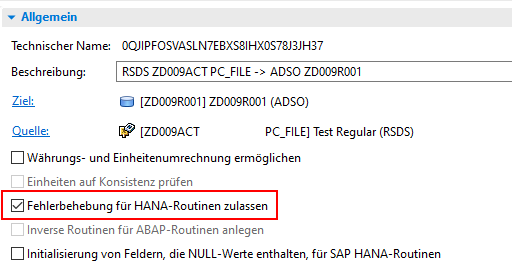
Die errorTab Tabelle besteht aus zwei Feldern: ERROR_TEXT und SQL__PROCEDURE__SOURCE__RECORD. Im Feld ERROR_TEXT können Sie die Beschreibung des Fehlers ausgeben. Das Feld SQL__PROCEDURE__SOURCE__RECORD dient als Kennung für den jeweiligen Datensatz.
Um die Funktionsweise des Error Stacks zu verdeutlichen, nutzen wir eine AMDP-Routine, die alle Felder unverändert übernimmt. Gleichzeitig wird die Spalte COMP_CODE auf ungültige Zeichen geprüft und die fehlerhaften Datensätze in die Tabelle errorTab geschrieben. Dabei nutzen wir den Befehl LIKE_REGEXPR, welcher Suchmuster basierend auf Perl Compatible Regular Expression (PCRE) erkennt. Dabei prüfen wir mit dem Muster [lower], ob das Feld Kleinbuchstaben enthält. Außerdem nutzen wir den Befehl LIKE, um alle Datensätze zu finden, die mit einem Ausrufezeichen anfangen. Schließlich definieren wir auch alle Buchungskreise als fehlerhaft, die den Wert # (nicht zugeordnet) haben.
outTab =
SELECT comp_code, currency, '' as recordmode, amount, record, SQL__PROCEDURE__SOURCE__RECORD
FROM :inTab;
errorTab= SELECT 'Check field value!' AS ERROR_TEXT,
SQL__PROCEDURE__SOURCE__RECORD
FROM :intab
WHERE comp_code LIKE_REGEXPR '.*[[lower]].*'
OR comp_code LIKE '!%'
OR comp_code = '#';Die Datenquelle enthält zwei falsche Datensätze - die Buchungskreise (0COMP_CODE) !200 und #.
|
0COMP_CODE |
0AMOUNT |
0CURRENCY |
|
1000 |
100,00 |
EUR |
|
!200 |
200,00 |
EUR |
|
# |
300,00 |
EUR |
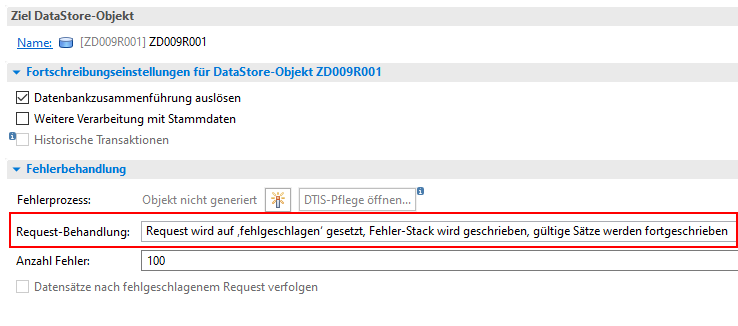
Des Weiteren nehmen wir im DTP folgende Einstellungen vor. Zum einen muss die Fehlerbehandlung eingeschaltet werden. Wechseln Sie dazu in den Reiter Aktualisieren und wählen Sie unter Fehlerbehandlung die Option Request wird auf fehlgeschlagen gesetzt, Fehler-Stack wird geschrieben, gültige Sätze werden fortgeschrieben aus.
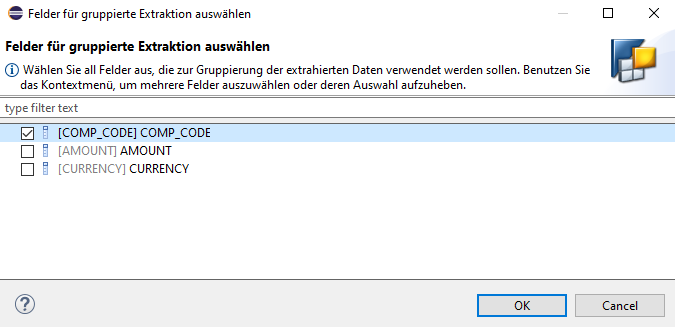
Für die Behandlung auf der HANA Datenbank müssen wir auch Semantische Gruppen definieren. Diese dienen der Bestimmung von fehlerhaften Datensätzen. So können wir zum Beispiel im Falle einer Bestellung und Bestellposition die Bestellung als Schlüssel festlegen. Wenn eine Position falsch ist, wird der gesamte Beleg als falsch markiert.
In unserem Beispiel ist es recht einfach - der Buchungskreis 0COMP_CODE dient als Schlüssel. Selektieren Sie daher bei der Einstellung Extraktion gruppiert über das Merkmal COMP_CODE.
|
Hinweis: |
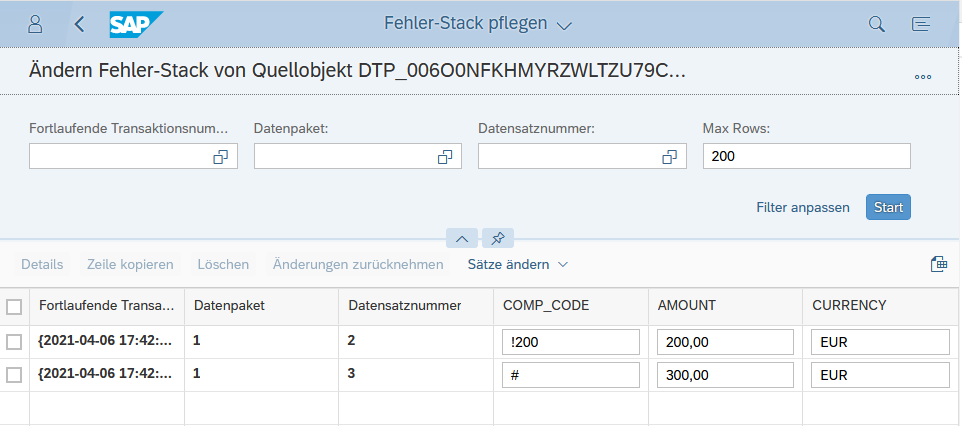
Wenn die SQLScript Routine nun ausgeführt wird, werden die fehlerhaften Buchungskreise identifiziert. Anhand der SQL__PROCEDURE__SOURCE__RECORD ID werden diese mit entsprechender Fehlermeldung in die Tabelle errorTab geschrieben.
Wie Sie auf den Screenshots erkennen können, handelt es sich dabei um die Buchungskreise !200 und #. Also Datensätze 2 und 3.
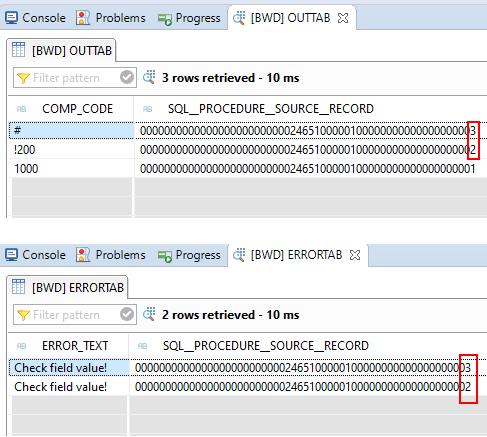
Nach der Ausführung der Routine landen diese Datensätze im Fehler-Stack.
Steigern Sie die Leistung Ihres BW mit SQLScript

Je nach Anforderung können Sie dieses Beispiel um weitere zu prüfende Felder erweitern. In der Praxis müssen Sie jedoch nicht alle Felder prüfen. Erfahrungsgemäß treten Fehler eher bei Feldern ohne Prüftabelle und bei Feldern, die in der Quelle manuell geändert werden, auf. In der nachfolgenden Tabelle sehen Sie eine Übersicht über die regulären Ausdrücke, die Sie verwenden können.
|
Ausdruck |
Beschreibung |
|
a% |
Wert fängt mit “a” an |
|
%a |
Wert endet mit “a” |
|
%a% |
Wert hat “a” an einer beliebigen Stelle |
|
_a% |
Wert hat “a” an der zweiten Stelle |
|
a_% |
Wert fängt mit “a” an und ist mindestens zwei Zeichen lang |
|
a%z |
Wert fängt mit “a” an und endet mit “z” |
|
[abc] |
“a”, “b” oder “c” |
|
[a-z] |
Kleinbuchstaben |
|
[A-Z] |
Großbuchstaben |
|
[0-9] |
Ziffer |
|
. |
Beliebiges Zeichen |
|
[[:digit:]] |
Ziffern 0-9, entspricht dem Ausdruck [0-9] |
|
[[:lower:]] |
Kleinbuchstaben, entspricht dem Ausdruck [a-z] |
|
[[:upper:]] |
Großbuchstaben, entspricht dem Ausdruck [A-Z] |
|
[[:alpha:]] |
Alle Buchstaben, entspricht den Ausdrücken [a-z] und [A-Z] sowie [[:lower:]] und [[:upper:]] |
|
[[:alnum:]] |
Alle Groß- und Kleinbuchstaben sowie alle Ziffern. Entspricht den Ausdrücken [:alpha:] und [:digit:], also [A-Z,a-z,0-9] |
|
[[:punct:]] |
Satzzeichen, z.B.: . , " ' ? ! ; : # $ % & ( ) * + - / < > = @ [ ] \ ^ _ { } ~ |
|
[[:print:]] |
Alle druckbaren Zeichen, entspricht den Ausdrücken [:alnum:] , [:punct:] sowie SPACE |
|
[[:graph:]] |
Alle druckbaren Zeichen ohne SPACE, entspricht den Ausdrücken [:alnum:] und [:punct:] |
|
[[:blank:]] |
Beinhaltet SPACE und TAB |
|
[[:space:]] |
Beinhaltet alle whitespace Zeichen: SPACE, TAB, CR, FF, NL, VT. |
|
[[:cntrl:]] |
Beinhaltet Steuerzeichen: ACK CAN CR DC1 DC2 DC3 DC4 DEL DLE EM ENQ EOT ESC ETB EXT FF IS1 IS2 IS3 IS4 LF NAK NL NUL SI SO SOH STX SUB TAB VT |
|
[[:xdigit:]] |
Beinhaltet hexadezimale Ziffern (0-9, A-F, a-f) |
|
[[=a=]] |
Beinhaltet äquivalente Zeichen. Zum Beispiel alle Buchstaben, die auf „a“ basieren. Wie ä, à, â, á, usw. |
Planen Sie einen Umstieg auf SQLScript und benötigen Sie Unterstützung bei der Planung der richtigen Strategie? Oder benötigen Sie erfahrene Entwickler zur Umsetzung Ihrer Anforderungen? Zögern Sie nicht, uns zu kontaktieren - wir beraten Sie gerne.


