






















Apache Airflow stellt sich selbst als Community-basierte Plattform für programmatisches Workflow-Management und Orchestrierung dar. Für Datenteams, die für ETL-Pipelines oder Workflows für Machine Learning zuständig sind, sind dies wichtige Funktionen und ein codebasiertes System könnte genau die Stärken der technisch versierten Teammitglieder ausspielen. Ihre eigene Airflow-Instanz ist anhand der offiziellen Projektdokumentation schnell eingerichtet, wirft aber sofort eine Reihe von Fragen für den Produktivbetrieb auf. Einige der Herausforderungen sind:
- Entscheidung über Bereitstellungsprozesse für Systemumgebungen der Entwicklungs-, Test- und Produktionsphase
- Festlegung eines soliden Rahmens für die Entwicklung von Arbeitsabläufen in diesen Phasen
- die richtige Menge an Regeln und Konventionen zu finden, damit sich alles nahtlos in Ihren spezifischen Anwendungsfall einfügt
Apache Airflow ist ein leistungsfähiges Tool mit vielen Vorteilen, das jedoch einer sorgfältigen Anpassung bedarf, um sich perfekt in eine bestimmte Prozesskette zu integrieren. In der heutigen Sammlung von Praxistipps geben wir Ihnen einen Überblick über einige häufige Herausforderungen, Lösungsansätze und ein praktisches Einsatzbeispiel!
Herausforderungen
Um einige der Herausforderungen zu verstehen, die Airflow für das Betriebsteam mit sich bringt, führen wir uns zunächst die Funktionsweise von Airflow vor Augen: Wie die obige Definition deutlich macht, ist Airflow eine Plattform, die sich an Personen mit einschlägigen Programmierkenntnissen richtet. Es gibt keine Benutzeroberfläche zur Erstellung von Workflows (oder "directed acyclic graphs", DAGs). Wenn Sie möchten, dass Airflow mehr als einen der Beispiel-DAGs ausführt, müssen Sie einen Python-Code schreiben. Sobald der Python-Code für Ihren ersten DAG fertig ist, müssen Sie diese Datei in das richtige Verzeichnis Ihres Airflow-Systems legen, damit sie erkannt wird. Auch hier gibt es keine Benutzeroberfläche zum Hochladen Ihres neuen DAG.
Eine grundlegende Konvention der DAG-Entwicklung besagt, dass Sie keinen benutzerdefinierten Code in die DAG-Definitionsdatei einfügen sollten. Wenn Sie einen eigenen Code ausführen möchten (z. B. wenn nicht alle Ihre Prozessschritte von den vorhandenen Operatoren oder Sensoren erfüllt werden), müssen Sie diesen Code an anderer Stelle in der Airflow Python-Umgebung platzieren, um ihn in Ihrem DAG aufzurufen.
All dies ist schnell herausgefunden und auf einem einzelnen Computer erledigt, auf dem Sie alle Airflow-Komponenten als Docker-Container unter Verwendung von Compose-Dateien ausführen, für die es im Internet zahlreiche Beispiele gibt. Sobald diese Prozesse aber in einer mehrstufigen Entwicklungs-/Test-/Produktivumgebung laufen müssen, die von einem oder sogar mehreren Teams betrieben wird, wird es kompliziert:
Wie interagieren die DAG-Entwickler mit Airflow? Wie werden DAGs getestet? Wie und wann sollten DAGs und Plugins bereitgestellt werden? Wer ist für welchen Aspekt der Bereitstellungspipeline verantwortlich?
Es gibt nicht die eine richtige Methode, um diese Fragen zu beantworten, sondern viele verschiedene Ansätze, von denen wir einige diskutieren werden.
CI/CD und die Qual der Wahl
Die Begriffe Continuous Integration und Continuous Delivery (CI/CD) fassen Methoden und Strategien zur Verbesserung der Qualität von Softwareentwicklung durch automatisches Testen und Ausführen von Codes in der Zielumgebung zusammen. CI/CD-Frameworks ermöglichen alle Arten von automatisierten Prozessschritten auf der Grundlage von Änderungen am Quellcode (üblicherweise in einem Git-basierten Code Repository). Da Airflow und alle seine Komponenten im Quellcode definiert sind, liegt es nahe, mit CI/CD-Tools ein robustes Entwicklungs- und Bereitstellungs-Framework zu schaffen.
 Auch hier gibt es keine einzig richtige Methode der Umsetzung. Sie haben die Qual der Wahl zwischen verschiedenen CI/CD-Frameworks und Pipeline-Designs, bezüglich des Betriebs von Airflow und der Art und Weise, wie Ihre Teams arbeiten und miteinander kommunizieren. Für unser folgendes Beispiel haben wir uns für Gitlab CI/CD als Framework entschieden. Die gleichen Ergebnisse können aber mit jeder frei oder kommerziell verfügbaren Alternative erzielt werden, unabhängig davon, ob Ihre Infrastruktur Cloud-basiert ist und Sie integrierte CI/CD-Tools verwenden oder eine Verbindung zu einem Drittanbieterdienst wie Travis CI herstellen oder, ob Sie Zugang zu einer lokalen Instanz von Open-Source-Frameworks wie Jenkins, Drone oder Woodpecker CI haben. Wir werden hier nicht ins Detail gehen, sondern uns auf die Optionen konzentrieren, die Sie in Bezug auf Airflow haben.
Auch hier gibt es keine einzig richtige Methode der Umsetzung. Sie haben die Qual der Wahl zwischen verschiedenen CI/CD-Frameworks und Pipeline-Designs, bezüglich des Betriebs von Airflow und der Art und Weise, wie Ihre Teams arbeiten und miteinander kommunizieren. Für unser folgendes Beispiel haben wir uns für Gitlab CI/CD als Framework entschieden. Die gleichen Ergebnisse können aber mit jeder frei oder kommerziell verfügbaren Alternative erzielt werden, unabhängig davon, ob Ihre Infrastruktur Cloud-basiert ist und Sie integrierte CI/CD-Tools verwenden oder eine Verbindung zu einem Drittanbieterdienst wie Travis CI herstellen oder, ob Sie Zugang zu einer lokalen Instanz von Open-Source-Frameworks wie Jenkins, Drone oder Woodpecker CI haben. Wir werden hier nicht ins Detail gehen, sondern uns auf die Optionen konzentrieren, die Sie in Bezug auf Airflow haben.
|
Code Repository |
CI/CD Engine |
Deployment |
|
GitLab Azure Repos GitHub AWS CodeCommit Bitbucket Gitea … |
GitLab CI/CD Azure Pipelines AWS CodePipeline Bitbucket Pipelines Travis CI Jenkins Drone Woodpecker CI … |
Docker Kubernetes Python/PyPI … |
Für jede der Komponenten, die zur Erstellung einer durchgängigen DAG-Bereitstellungspipeline erforderlich sind, gibt es Alternativen.
Zunächst sollten Sie überlegen, ob Sie die Bereitstellung Ihrer Airflow-Plattform eng oder lose mit dem Airflow-DAG-Entwicklungsprozess koppeln möchten. Eine enge Kopplung kann durch die Erstellung eines benutzerdefinierten Airflow Docker-Images erreicht werden, das alle Ihre benutzerdefinierten DAGs (und deren Abhängigkeiten) enthält. Dies ist kompakt und zunächst einfach eingerichtet, aber Ihr gesamtes System muss jedes Mal komplett neu bereitgestellt werden, wenn Änderungen an einem DAG vorgenommen werden. Eine lose Kopplung kann durch eine strikte Trennung von Airflow-Plattform und DAG-Entwicklung erreicht werden. Geänderter DAG-Code würde in das laufende Basissystem eingespeist werden, ohne dass alle Systemteile neu ausgerollt würden. Welcher Weg zu wählen ist, hängt von einer Reihe von Faktoren ab, die spezifisch für Ihre Umgebung sind. Dies können beispielsweise die Anzahl der DAGs sein, die Sie betreiben wollen, die Anzahl der Teams oder Personen, die DAGs entwickeln, die Komplexität der DAGs selbst und wie viele benutzerdefinierte Python-Modul-Abhängigkeiten sie mit sich bringen.
Im Allgemeinen skaliert eine lose Kopplung besser mit der Anzahl der DAGs, der Entwickler oder wenn die Verantwortlichkeiten für Workflows auf mehrere Teams verteilt sind. Enge Kopplung kann die Komplexität Ihres Frameworks reduzieren, da die Aufgaben an einer Stelle zentralisiert sind. Ein Wechsel zwischen den beiden Ansätzen ist möglich, wenn sich die Umstände ändern, z. B. wenn das System im Laufe der Zeit wächst, allerdings zu den üblichen Kosten einer Änderung bereits etablierter Routinen. Keiner der beiden Ansätze entkoppelt den Betrieb der Plattform vollständig von der Entwicklung der DAGs, aber die Entscheidung hat Einfluss darauf, wie Sie die eigentliche CI/CD-Pipeline und mögliche Pipeline-übergreifende Interaktionen gestalten müssen.
|
Bereitstellungsmodell |
enge Kopplung |
lose Kopplung |
|
Vorteile |
|
|
|
Nachteile |
|
|
Vergleich der Vor- und Nachteile zwischen eng und lose gekoppeltem Bereitstellungsmodell von Airflow und DAGs.
Gehen wir von einer lose gekoppelten Bereitstellung aus und konzentrieren wir uns auf den DAG-Entwicklungsworkflow. CI/CD-Pipelines für die DAG-Entwicklung sollten Entwicklern eine einfache Möglichkeit bieten, neue DAGs zu erstellen, sie automatisch isoliert (Unit Tests) und im Kontext (Integrationstests) zu testen. Sie sollten von mindestens einem weiteren Entwickler zu überprüfen und in die Zielumgebung zu implementieren sein. Anschließend übernimmt die Airflow-Plattform die Orchestrierung und startet die Aufgaben wie geplant. Eine gut definierte CI/CD-Pipeline kann die Verantwortung der Entwickler auf die Bereitstellung von neuem DAG-Quellcode (und Testdefinitionen) an der richtigen Stelle, d.h. dem richtigen Git-Repository, reduzieren.
Optimieren Sie Ihr Workflowmanagement
mit Apache Airflow!

Wie Sie Ihre CI/CD-Pipeline gestalten, hängt davon ab, wie das/die Airflow-System(e) bereitgestellt werden und wie codebasierte Artefakte in das System verteilt werden müssen. Dies kann bedeuten, dass Sie die DAG-Dateien in das richtige Verzeichnis im Dateisystem des Host-Servers bereitstellen oder die Dateien in einen Object-Storage-Dienst hochladen, z. B. AWS S3, wenn Sie einen von Amazon verwalteten Cloud-basierten Airflow-Dienst verwenden.
Um diese Büchse der Pandora wieder zu schließen, wollen wir uns ein Praxisbeispiel ansehen, wie wir bei NextLytics eine interne Entwicklungsumgebung eingerichtet haben.
Praxisbeispiel: GitLab CI/CD
In diesem Beispiel verwenden wir GitLab als Versionsverwaltungssystem für den Quellcode und das integrierte GitLab CI/CD-Framework zur Automatisierung von Tests und Bereitstellung. Wir verfolgen einen Ansatz mit loser Kopplung und trennen die Bereitstellung und den Betrieb des Airflow-Basissystems vom DAG-Entwicklungsprozess. Das Airflow-System wird auf einem entfernten Host-Server unter Verwendung der Docker-Engine dieses Servers ausgeführt. Python-Module, Airflow-DAGs, Operatoren und Plugins werden in das laufende System verteilt, indem die Dateien in bestimmten Dateisystemverzeichnissen auf dem Remote-Host abgelegt/aktualisiert werden, welche in die Docker-Container eingebunden werden. Die Option "lazy loading" der Airflow Konfiguration wurde dabei deaktiviert, damit das System regelmäßig nach geänderten/aktualisierten Modulen sucht.
Alle DAGs für die Airflow-Instanz werden in einem einzigen Git-Repository (einem Projekt in GitLab) entwickelt. Eine Überprüfung des Quellcodes wird durch die GitLab-Einstellungen erzwungen: Änderungen können nur über einen Merge Request in den Hauptzweig übertragen werden, der wiederum eine Überprüfung durch ein zweites Augenpaar erfordert sowie den erfolgreichen Abschluss aller Testphasen der CI-Pipeline, bevor er abgeschlossen werden kann.
.png?width=850&name=02_gitlab-project-architecture%20(1).png) Vergleich der eng bzw. lose gekoppelten Architekturmodelle und wie die einzelnen Airflow Komponenten auf GitLab Projekte verteilt werden. Die rechts dargestellte lose gekoppelte Architektur entspricht dem vorgestellten Praxisbeispiel.
Vergleich der eng bzw. lose gekoppelten Architekturmodelle und wie die einzelnen Airflow Komponenten auf GitLab Projekte verteilt werden. Die rechts dargestellte lose gekoppelte Architektur entspricht dem vorgestellten Praxisbeispiel.
Der Quellcode ist in Unterverzeichnisse für DAGs, Airflow-Operatoren und benutzerdefinierte Python-Module unterteilt. Der Inhalt dieser Unterverzeichnisse wird während der Bereitstellungsphase der CI/CD-Pipeline in die Airflow-Laufzeitumgebung eingebunden.
Um neu entwickelte DAGs zu testen, müssen drei Stufen durchlaufen werden:
- Die Python-Syntax ist korrekt und alle Unit-Tests sind erfolgreich.
- DAG wird ohne Fehler in Airflow importiert (siehe Codebeispiel unten).
- DAG wird ohne Fehler in Airflow ausgeführt.
Die erste dieser Stufen ist insofern in sich geschlossen, als dass sie nur von dem geänderten Code und den damit verbundenen Tests abhängt, die der Entwickler implementiert hat. Für die zweite und dritte Stufe ist ein Airflow-System für die Testausführung erforderlich. Wir stellen diese Umgebung während der Ausführung der CI/CD-Pipeline zur Verfügung: Ein Wegwerf-Airflow-System wird mit Hilfe von Docker-Befehlen erstellt, die im CI/CD-Manifest angegeben sind, für die beiden Tests verwendet und danach wieder vollständig entfernt.
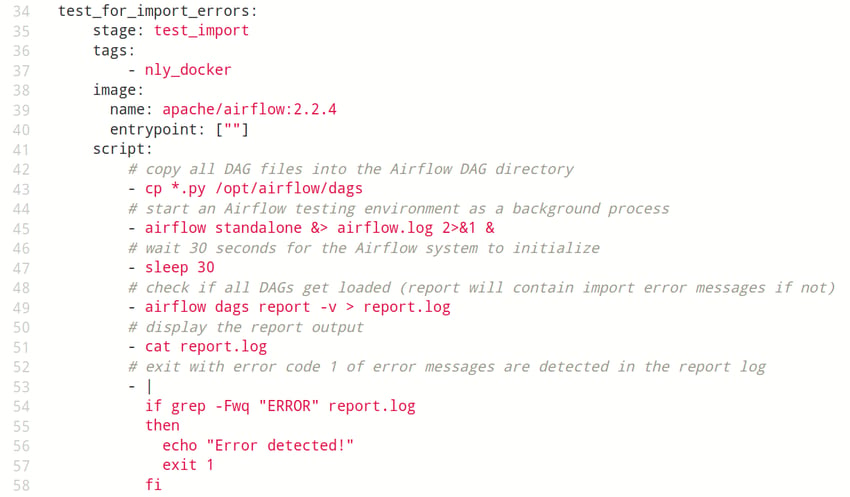
Codebeispiel: Eine GitLab CI/CD Job-Definition in YAML. Es werden Python Dateien mit DAG Definitionen in eine nur für diesen Zweck gestartete Airflow-Umgebung geladen und auf Importfehler geprüft.
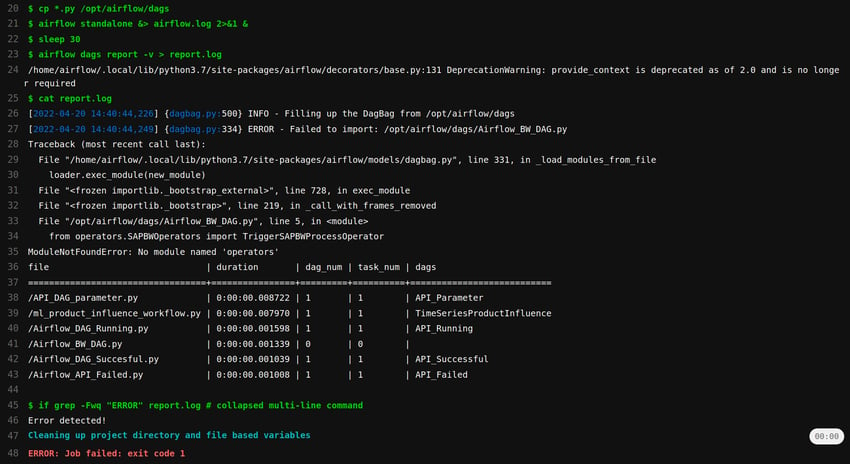
Beispiel Log: Das Protokoll einer Ausführung des obigen CI/CD Jobs in GitLab, wobei ein Importfehler erkannt wird. Es fehlt ein von einem DAG benötigter Operator, sodass der Job mit einem Fehler abbricht und den weiteren Verlauf der CI/CD Pipeline unterbricht.
Die Einzelheiten der Implementierung der Bereitstellungsphase der Pipeline sind wiederum der Konfiguration überlassen, da GitLab CI/CD mehrere Optionen bietet: Die Remotecodeausführung auf dem Hostserver kann durch Einrichtung eines dedizierten "GitLab Runner"-Dienstes oder durch Remoteanmeldung über das SSH-Protokoll ermöglicht werden. Die Bereitstellung der geänderten Dateien kann durch explizites Pushen in das entfernte Dateisystem oder durch Auschecken des gesamten Git-Repositorys auf dem entfernten Host erfolgen. Die Entscheidung kann von vielen Faktoren abhängen, wie z. B. von Konventionen, Routinen oder einfach von den Vorlieben der beteiligten Personen. In unserem Beispiel werden die SSH-basierte Fernanmeldung sowie die SCP-basierte Übermittlung von Dateien verwendet, da diese die Annahmen über den erforderlichen Zustand unseres Hostsystems reduzieren.
Das beschriebene Beispiel zeigt eine Möglichkeit, die Entwicklung, das Testen und die Bereitstellung von DAGs mithilfe der CI/CD-Automatisierung von GitLab zu handhaben. Die Implementierung aussagekräftiger Tests bleibt weitgehend den Entwicklern überlassen, und die Schaffung der erforderlichen einmaligen Umgebung für vollständige Integrationstests erfordert tiefergehende Kenntnisse sowohl des CI/CD-Frameworks als auch der Dienste von Drittanbietern, mit denen die DAGs interagieren müssen.
GitLab CI/CD - Unser Fazit
Es sind viele variable Bausteine erforderlich, um einen gut definierten, robusten und anwendungsspezifischen Betriebsrahmen für Apache Airflow und die Entwicklung von DAGs zu schaffen. Die Fülle an Auswahlmöglichkeiten und Alternativen verfügbarer Tools und Implementierungsdetails erfordert ein tiefgreifendes Verständnis des Ökosystems und der spezifischen Anforderungen des Szenarios.
Unser Beispiel zeigt einen möglichen Ansatz unter Verwendung von GitLab CI/CD als Framework. Im produktiven Einsatz können die Konventionen der Teams und die gemeinsamen Verantwortlichkeiten der Beteiligten wichtigere Faktoren für die Gestaltung des CI/CD-Prozesses sein als technologische Funktionalität. Wenn Sie ein passendes Airflow-Operations-Framework einrichten möchten oder ein Expertenfeedback zu Ihrer aktuellen Implementierung wünschen, nehmen Sie gerne direkt Kontakt mit uns auf!


