/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























With the continued adoption of AI across all levels of business and the increasing reliance on statistics-based modeling, the trend is to bring AI modeling closer to actual end users. Many data analytics platforms provide simple functions for users to add machine learning approaches to their analytics without code. With such self-service AI, the data science department is only involved in providing dynamic modeling frameworks and a suitable database. Especially when the self-service idea is complemented by the possibility to add external data, the design holds some challenges.
In this article, we will introduce you to the approaches available for providing external data for self-service analyses by business users. In our example use case, we show you how external factors can be dynamically integrated into a time series analysis.
Challenges in the integration of external data
The integration of external data into business analyses is necessary nowadays, as more complex questions can no longer be answered with purely internal data. However, in traditional machine learning modeling, data sources are integrated in a fixed way for the specific use case, which offers no flexibility and only limited portability. If business users want to have an easy way to integrate data on weather, economy, environment and geography into their problem analyses, new challenges arise for the technical realization:
- Restricting access to data sources
- Ensuring data security
- Provision of different data formats
- Sufficient data quality for usability
To meet the challenges, there are a number of tools that guide the external data to the analytics. The design is arbitrarily simple or complex.
Deployment maturity levels
There are different levels of maturity as to how the provisioning of external data for use in self-service modeling can be implemented. The classification is based on the decreasing responsibility on the part of data preparation and modeling design.
- Availability in your own data lake
- Integration into a feature store
- Integration in a dynamic modeling
The following overview lists the Business User's responsibilities per deployment.
%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-1.png?width=600&name=2022-03-17%20(EN)%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-1.png) Distribution of responsibilities for work steps between self-service users and data science/engineering teams.
Distribution of responsibilities for work steps between self-service users and data science/engineering teams.
Availability in your own data lake
The simplest way to make external data available is via a data lake. Linked to a metadata management system or data catalog, it contains important information about up-to-dateness and versioning. Access rights and encryption are also regulated. However, users must structure and prepare the data themselves, as well as merge it with the actual analysis data.
A good example of this implementation is the data management tool SAP Data Intelligence. A data lake with extensive metadata management is integrated into it, which supports users in implementing their analysis ideas. Data packages can be easily uploaded and published for other users.
Depending on the division of responsibilities, the loading of data can be controlled and automated by the data engineering team or can be done by the end users themselves.
%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-1.png?width=700&name=2022-03-17%20(DE)%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-1.png)
Published data in the Metadata Explorer of SAP Data Intelligence. Data in csv format is stored in the integrated Data Lake.
Advance your business through Artificial Intelligence and Machine Learning - Download the Whitepaper here!

Feature Store integration
If the management responsibility for the external data is to be shifted further towards the data engineering team and away from the users, the use of a feature store is suitable.
As an additional abstraction layer between data sources and AI modeling, the required data is provided in the form of feature groups. Preprocessing is performed here and a feature register helps to find suitable influencing factors. In particular, the matching of data can already be done here using on-board means of the system and facilitate further processing. Examples of AI self-service platforms with an integrated feature store are Amazon SageMaker, Azure Databricks or the Hopsworks Machine Learning Framework.
Other self-service platforms may not have an explicit feature store integrated. However, validations and transformation rules (including joins) can be applied to the data and made available in a modified form. In terms of shared responsibility for the process, this variant represents a middle ground between pure provisioning and centralization in the feature store.
Integration in a dynamic modeling
Especially considering the development of an internal offering for self-service AI, providing the external factors as usable data is not a complete solution. The modeling step must be complemented by parameterization and automation.
The modeling is usually dynamically controlled via a REST interface, which allows easy integration into common BI tools. In addition to the availability of selectable external factors, the existing functions can also be extended and new model types can be integrated.
The database and the end users are strictly separated. Restricting access leads to standardization and more data security through centralized control. The lost flexibility can mostly be compensated by a targeted design of the modeling options according to the created specification.
The possibilities of this variant can be well explained by a practical application example for the dynamic generation of time series analyses.
Application idea: Automated time series with a dynamic selection of influencing factors
Time series analyses can be excellently automated and are applicable to a number of problems. While in the conventional sense only a value and its development over time including trends and seasonalities are considered, these can be supplemented by external factors. Especially when it comes to sales figures, the analysis of influencing factors yields interesting knowledge. Similarly, due to the large number of products, the product-specific analysis should be created as dynamically as possible.
How can this be implemented in a system? Several components play together here:
- Internal data
The time series data of the products must be available in an adjusted form. Here, a choice of granularity (monthly vs. daily values) can also be interesting for the business user.
- External data
The influencing factors must be available in the company or quickly obtained via a data API. If an API is used, the corresponding monitoring of costs and usage must also be integrated into the system. Matching to the granularity of the internal data must also be planned.
- Dynamic modeling
The modeling should be parameterized. The product selection, the model selection and the selected influencing factors are only determined when the analysis is executed. If desired, optional preparation steps and feature engineering can also be parameterized or automated.
- Orchestration of the training
The execution of the modeling and the writing back of the results can be conveniently executed via a workflow management tool such as Apache Airflow, insofar as it supports parameterization. There, the execution is organized in containers and scaled appropriately.
- Front-end for user input
A simple user interface allows the user to start the analysis as needed and evaluate results. Web-based front-ends can be easily integrated into other applications such as NextTables as an iFrame. In addition, BI platforms such as Tableau, SAP Analytics Cloud or Power BI usually offer the option to integrate custom processing logic into dashboards via REST interface with little to no programming effort.
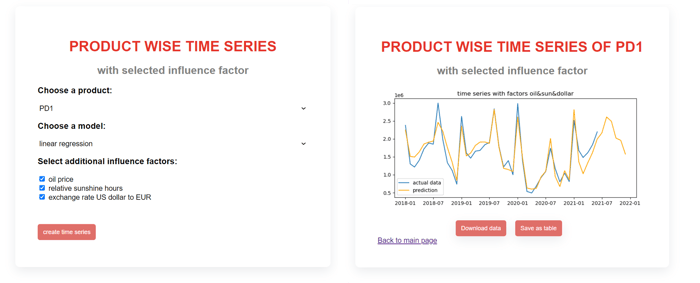 Functions for product selection, model selection and the integration of additional influencing factors are stored in a simple front end.
Functions for product selection, model selection and the integration of additional influencing factors are stored in a simple front end.
A presentation of the results can also be done here or in connected BI tools.
Of course, the use case does not end with the display of a result. The data itself can be used in planning scenarios or a downstream reporting evaluates the respective influence of the factors with selected key figures. Apt modeling can also be used for forecasting purposes.
Self-Service Analytics - Our Conclusion
Overall, external data is a comprehensive way to improve the performance of models. The provision for business users in self-service AI applications can take place at different levels. The addition of external factors can be easily automated, especially for sales forecasts, and enables precise analyses even for a large product range.
Do you need support integrating external data into your machine learning workflows? Feel free to contact us. We can help you in all project phases from system design to user-centric implementation.

