























Alle Geschäftsbereiche Ihres Unternehmens steuern die Prozesse rund um die Daten, die sie erzeugen und verwenden. Sie sind stolz darauf, ihren Kollegen aus anderen Abteilungen qualitativ hochwertige Daten zur Verfügung zu stellen. Sie verfügen über alle notwendigen Werkzeuge und Kenntnisse, um Änderungen an diesen Daten und ihren Verarbeitungsabläufen selbst vorzunehmen. In einer abteilungsübergreifenden Zusammenarbeit, die alle Beteiligten zu souveränen Akteuren mit einem klaren Zielverständnis macht, wird aus den Daten Ihres Unternehmens ein messbarer geschäftlicher Nutzen gezogen. Klingt zu schön, um wahr zu sein? Dann lassen Sie uns über das Konzept des Data Mesh sprechen.
Data Mesh ist eines der angesagtesten Schlagworte in der Business Data Community. Das Konzept ist aus der wissenschaftlichen Betrachtung von Erfolgsfaktoren und Hürden bei der Umsetzung von Data Warehouse und Data Lake Architekturen entstanden. Wie gut funktionieren in diesen Architekturen unternehmensweite Datenstrategien, Daten- und Informationsverteilung zwischen den Stakeholdern sowie der zugrunde liegenden technischen Architektur und Prozesse? Die Erkenntnis daraus lautet: Klassisches zentralisiertes Data Warehousing und der weniger streng kuratierte Data Lake-Ansatz führen zu massiven Ressourcenengpässen, wenn es darum geht, Änderungen umzusetzen.
Diese von IT- und Datenverarbeitungsexperten entworfenen Architekturen stützen sich auf dasselbe technische Fachwissen, um zentrale Dienste für vorgelagerte Datenproduzenten und nachgelagerte Datenkonsumenten bereitzustellen. Produzenten und Konsumenten sind in der Regel Fachabteilungen, die für ihre Daten und die daraus gewonnenen Erkenntnisse verantwortlich sein sollten. Stattdessen sind sie jedoch von den Data-Warehousing- oder Engineering-Teams abhängig, die die Infrastruktur und die Datenexporte in ihren Aufträgen anpassen müssen. Wenn diese Ressourcen knapp werden, wird ein formelles Servicemanagement eingeführt, das eine klar definierte Auftrags- und Versorgungslinie zwischen den Abteilungen zieht, um die verfügbaren Kapazitäten besser zu verteilen. Das verkompliziert die Dinge zusätzlich, obwohl alle Beteiligten gerne effizient sinnvollen Aufgaben nachgehen und Erkenntnisse oder Mehrwert für das Unternehmen generieren wollen.
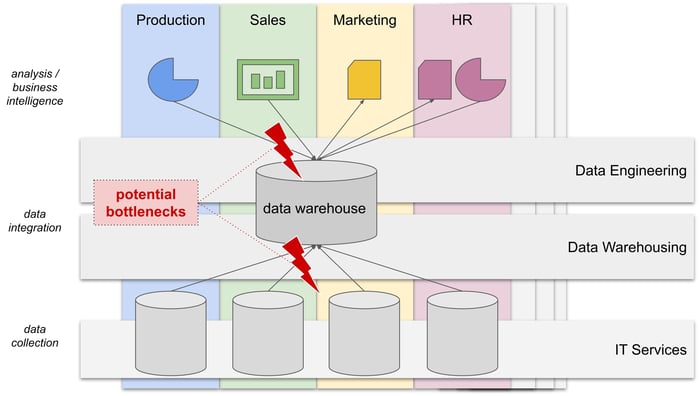
Eine klassische Data-Warehousing-Architektur mit zentralisierten, funktionsorientierten Teams für Warehouse-Management
und Data Engineering kann zu Engpässen in den datengesteuerten Wertschöpfungsprozessen eines Unternehmens führen.
Die Geschäftsbereiche haben keine Kontrolle über die Daten, die sie produzieren oder verbrauchen.
Wie unterscheidet sich der Ansatz des Data Mesh? Wie könnte eine andere technische Architektur diese organisatorischen Herausforderungen bewältigen?
Das Data Mesh wird von vier Hauptprinzipien getragen:
- Daten werden wie ein Produkt behandelt.
- Dezentralisierte Domänen Teams sind Eigentümer der Daten, die sie produzieren und nutzen.
- Alle Teams haben Zugang zu einer Self-Service-Infrastruktur für Datenverarbeitung und -speicherung.
- Die Datenverwaltung wird durch ein föderiertes technisches Governance Modell gesteuert.
Data Mesh ist also offensichtlich nicht nur ein technologischer Ansatz, sondern umfasst auch Aspekte der Organisationsstruktur, der Prozesse und sogar der Unternehmenskultur. Es wurde von Anfang an als "soziotechnischer" Ansatz deklariert, der sowohl soziale als auch technologische Prozesse innerhalb von Organisationen in die Gleichung mit einbezieht. Mehr noch: Es gibt keine schlüsselfertige Software, die man einfach kaufen, einführen und so ein erfolgreiches Datennetz implementieren kann. Die Implementierung ist ein hochgradig individueller Prozess für jede Organisation. Der Grund dafür ist der prozessorientierte Charakter der Definition des Data Mesh selbst, die mit einer beliebigen Anzahl und Kombination von Softwarelösungen erreicht werden kann, je nach den Präferenzen der beteiligten Akteure.
Im Kern geht es beim Data Mesh um die Dezentralisierung von Verantwortung als Mittel zur Skalierung der Infrastruktur. Gleichzeitig werden die Datenproduktteams zu selbstverwaltenden Akteuren und Kuratoren für die Daten, die sie besitzen und mit anderen Teams teilen. Die Verantwortung für die in den Daten kodierten Informationen wird an die Personen zurückgegeben, die über das entsprechende Fachwissen verfügen.
So kurbeln Sie Ihr Business durch
Künstliche Intelligenz und Machine Learning an

Die hohen Ideale des Data Mesh haben den Preis, dass ein strenges und maschinell umsetzbares Governance-Modell geschaffen werden muss. Es wird ein Metadatenkatalog benötigt, der alle Datenprodukte erfasst. Wer für sie verantwortlich ist, wie sie produziert werden, welche Qualität zu erwarten ist, wer auf die Daten zugreifen darf und wer für die Gewährung des Zugriffs zuständig ist, wie die Daten abgerufen werden können und schließlich welche anderen Datenprodukte von diesem Element abhängen. Diese Verbindungen zwischen den Datenprodukten bilden die namensgebende Netztopologie des Data Mesh.
Soziale Aspekte des Übergangs zu einer Data Mesh Architektur sind nicht nur die neuen Verantwortlichkeiten und Rollen innerhalb der Domänen-Teams (in der Regel Fachabteilungen oder kleinere Gruppen innerhalb dieser) und deren Interaktion, sondern auch teamübergreifend. Die Governance und die gegenseitigen Abhängigkeiten von Datenprodukten erfordern belastbare und skalierbare Prozesse für alle Beteiligten im Netz. Wie wir alle bereits aus unserem demokratischen politischen System oder der Methodik der agilen Projektarbeit wissen: Ein hohes Maß an Freiheit und Selbstverwaltung erfordert strenge Regeln und Verantwortlichkeiten. Es ist kein Zufall, dass bei der Diskussion von Konzepten und Prinzipien des Data Mesh oft von Datendemokratisierung (engl. “democratization”) und Datenbürgerschaft (“citizenship”) die Rede ist.
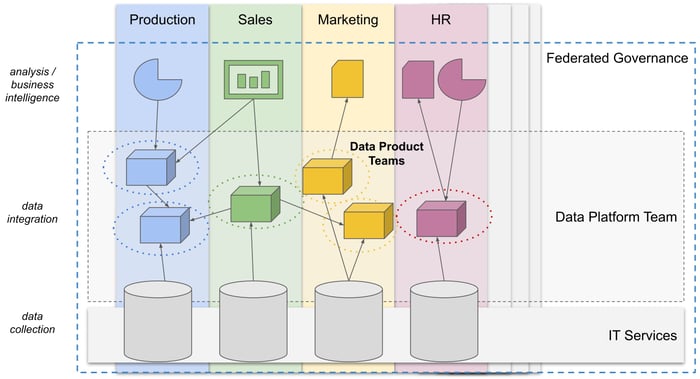
Der Data-Mesh-Ansatz zielt darauf ab, die Verantwortung für die Daten an die Geschäftsabteilungen zurückzugeben,
in denen das volle Verständnis und die Kompetenz für die Handhabung und Interpretation dieser Daten ursprünglich angesiedelt sind.
Neu zugewiesene Datenproduktteams verwenden Self-Service-Tools, um ihre jeweiligen Güter zu erstellen,
zu kuratieren und sie entlang wertschöpfender Geschäftsprozesse zu teilen.
Der Data Mesh Ansatz folgt einem übergreifenden Trend in der Technologie hin zu verantwortungsbewussten und selbstorganisierenden Teams. Er überträgt Erkenntnisse und bewährte Praktiken aus der Software Engineering Praxis in einen weniger erforschten Bereich. Die Anpassung von Datenprodukten an genau definierte Metadatenmodelle und die Festlegung von Computational Governance sind Übersetzungen von Mustern, die aus dem Software Dependency Management bekannt sind. Die Aufteilung von Aufgaben und Verantwortlichkeiten in für sich abgeschlossene Probleme wurde bereits erfolgreich in Domain Driven Design, Microservices-Architekturen und agilen Management-Frameworks umgesetzt. Data Mesh ist eine logische Weiterentwicklung der Art und Weise, wie Datenverarbeitung skaliert werden kann, unabhängig von der Größe oder Kapazität technischer Datenbanken und Datenplattformen.
Klingt großartig, aber nach einer Menge Arbeit? Deshalb beginnt die Reise in das Data Mesh mit strategischen Fragen zu den Zielen und Beweggründen und der Entscheidung, ob diese Reise letztendlich notwendig ist. Wenn Ihr Unternehmen unter einigen der eingangs beschriebenen Herausforderungen leidet und nach anfänglichen strategischen Diskussionen die Entscheidung für eine Data Mesh Architektur fällt, ist die Umstellung ein schrittweiser sukzessiver Prozess. Die Schaffung der organisatorischen und technischen Infrastruktur für die Implementierung eines Data Mesh ist ein Prozess des ständigen Lernens und der Anpassung an die spezifischen Anforderungen der Gegebenheiten in Ihrem Unternehmen. Viele Teile des Puzzles liegen auch schon auf dem Tisch, wie einige unserer früheren Blogbeiträge zeigen: Die Dezentralisierung wird zunehmend durch Plattformsoftware unterstützt, seien es SAP Data Warehouse Lösungen, integrierte Data-Science-Plattformen oder hochspezifische Plattformkomponenten wie Self-Service Feature Stores für Machine-Learning-Entwickler. IT- und Datenverarbeitungsfähigkeiten verbreiten sich über Fachabteilung hinweg, da Datenkompetenz von Unternehmen zunehmend thematisiert und gefördert wird, wodurch die Grundlage für dezentrale Datenhoheit geschaffen wird.
Wir erleben häufig, dass Diskussionen über die Datenstrategie von Unternehmen und die Architektur von Datenplattformen auf die Themen der Datendemokratisierung und die Herausforderungen, die mit dem Data Mesh Ansatz adressiert werden. Wenn sich der Trend in der gleichen Weise fortsetzt, wie sich (Software-)Engineering Best Practices und agile Management Methoden über die IT-Abteilungen hinaus in das Gefüge von Organisationen ausgebreitet haben, stellt sich nicht die Frage, ob man das Potenzial der Übernahme dieser Konzepte analysieren sollte, sondern wann.
Wir hoffen, dass dieser Überblick über den Ansatz der Datenvernetzung, seine Beweggründe und potenziellen Vorteile, Ihnen geholfen hat, dieses Trendthema besser zu verstehen. Wenn Sie die spezifischen Anforderungen Ihres Unternehmens erörtern und herausfinden möchten, ob Data Mesh für Sie von Vorteil sein könnte, freuen wir uns darauf, mehr über Ihre Herausforderungen zu erfahren und helfen Ihnen gerne dabei, optimale Lösungen zu finden und umzusetzen.

