






















Künstliche Intelligenz (KI) und Machine Learning (ML) Projekte gewinnen immer mehr an Attraktivität in deutschen und internationalen Unternehmen. Der Aufwand wird jedoch häufig unterschätzt, während die Ergebnisse eines solchen Projektes durch unrealistische Erwartungen überschätzt werden können. Im schlimmsten Fall kann die Umsetzbarkeit eines ML Modells nicht ausreichend durch einen Prototypen (s. ML Workflow) bewiesen werden. Wer jedoch denkt, die Aufwendungen und bisher geleistete Arbeit wäre sinnlos gewesen, liegt falsch. In diesem Artikel zeigen wir Ihnen die Vorteile, Machine Learning Projekte einzusetzen und warum es sich in jedem Fall lohnt -abgesehen von dem eigentlichen Projektziel - ein KI Projekt in Ihrem Unternehmen zu starten.
Erhöhte Datenqualität
Ein ML Modell kann nur so gut sein, wie die Daten mit denen das Modell arbeitet. Nicht umsonst lautet ein weit verbreiteter Spruch “Garbage in, garbage out”. Das bedeutet, ein vorangestelltes Ziel eines ML Projekts, ist die Erhöhung der Datenqualität. Dazu zählt zum einen die Menge an Daten, die beschaffen werden muss als auch die Verarbeitung.
Bei der Datenbeschaffung werden interessante Schnittstellen sichtbar und bereits vorhandene Datenstrukturen erkannt und genauer analysiert. Dabei sollten unterschiedlichste Datenquellen für die Integration berücksichtigt werden. Die Menge und Relevanz der Daten, die benötigt werden, hängen vom ML Projekt und der leitenden Fragestellung ab. Beispielsweise sollte bei einer zeitlichen Vorhersage darauf geachtet werden, dass aktuelle, kontinuierliche Daten mit konkretem Zeitstempel vorhanden sind. Um typische Fehlerquellen frühzeitig zu detektieren und auszuschließen sollte bereits während der Datenerfassung eine Prüfung auf Plausibilität, Form und Richtigkeit durchgeführt wird.
Sind für das Projekt ausreichend Daten vorhanden, geht es an das Prozessieren der Daten. Tatsächlich verbringt ein Data Scientist die meiste Zeit seiner oder ihrer Arbeit mit der Datenvorverarbeitung und der Datenbereinigung (ugs. Data preprocessing und Data Cleansing). So sind beispielsweise fehlende Werte entweder zu filtern oder mit geeigneten Werten zu ersetzen bzw. zu imputieren. Auch sollte auf ein einheitliches Datenformat geachtet werden, um die Daten geeignet weiter zu verarbeiten. Das folgende Beispiel zeigt wie Data preprocessing und cleaning dafür sorgen kann die Daten zu korrigieren und so die Datenqualität zu erhöhen. Hierbei lag der Fokus auf Kundendaten, sodass jene Zeilen gefiltert bzw. entfernt wurden, denen keine eindeutige Customer ID zugeordnet werden konnte. Fehlende Werte für die Spalte “Revenue” hingegen wurden in Absprache mit der Fachabteilung durch Nullwerte ersetzt. Außerdem wurde der einheitliche Name “USA” eingeführt, um die Kunden dieser Region besser zusammenzufassen und zu analysieren.
 Beispiel für Data preprocessing und Data Cleansing
Beispiel für Data preprocessing und Data Cleansing
Wurde sich auf ein einheitliches Vorgehen bei der Datenprozessierung geeinigt, ist es ebenfalls möglich eine wiederverwendbare, generische Preprocessing-Pipeline zu implementieren. Dies hilft dem Unternehmen bei einer standardisierten Datenaufbereitung für verschiedenste Projekte. Das bedeutet, neben der eigentlichen Verwendung der Daten in einem ML-Modell, sind die Daten bereit für jegliche andere Analysen. Zusammengefasst sorgen gereinigte Daten dafür, dass Unternehmen mit einer höheren Zuverlässigkeit mit den Daten arbeiten können und so fundierte Entscheidungen treffen können.
Kurbeln Sie Ihr Business mit
Machine Learning und Künstlicher Intelligenz an

Data Discovery
Nachdem die Daten eine gewisse Qualität erreicht haben, können sie die erste Analyse durchlaufen. Meist erfolgt dies im Zuge einer visuellen EDA (explorative Datenanalyse). Diverse Plots und statistische Tests helfen in dieser Phase verschiedenste Annahmen über die Daten quantifizierbar zu bestätigen oder zu widerlegen. Dieser Schritt wird Data Discovery genannt, da man erste spannende
und teilweise unbekannte Einblicke in die Daten bekommt. Dabei werden technische Auffälligkeiten in fachliche Erkenntnisse übersetzt und Muster, Trends und Ausreißer herauskristallisiert. Dies ermöglicht, dass sich teamübergreifend fachfremde Mitarbeiter ohne
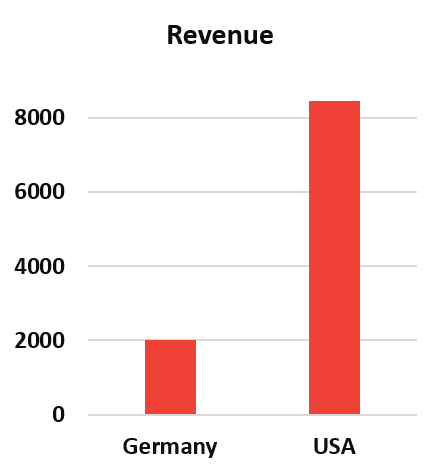
vertieftes Verständnis einen Überblick über die Daten verschaffen können. Unser Beispiel zeigt durch ein einfaches Balkendiagramm, dass die USA den größten Markt darstellt.
In diesem Schritt können sich weitere interessante Fragestellungen für Folgeprojekte anhand spezifischer Kennzahlen entwickeln, die dabei helfen die Effizienz und Produktivität eines Unternehmens zu steigern. Data Discovery dient als Entscheidungsgrundlage, da die Stärke eines Einflusses leichter abgeschätzt werden kann
Beispielbild Data Discovery
Entwicklung von Prozessen und Strukturen eines digitalen Teams
Abgesehen davon, wie ein KI Projekt ausgeht, hilft es dabei im Unternehmen ein digitales Daten-Team zu stärken, zu verbessern und ggf. sogar aufzubauen. Letzteres ist besonders für jene Abteilungen interessant und wichtig, die bisher wenig mit Big Data gearbeitet haben und/oder ihr erstes ML Modell entwickeln. Fachkompetenzen eines Data Scientists, Data Engineers und Machine Learning Engineers werden erlernt und ausgebessert. In unserem nächsten Blogartikel fassen wir Ihnen die Kernkompetenzen der jeweiligen Rollen kurz zusammen.
Damit eine fachübergreifende Zusammenarbeit ermöglicht werden kann, ist eine gute Dokumentation der einzelnen Entwicklungsschritte notwendig. Das stärkt nachhaltig das Verständnis und die Nachvollziehbarkeit für das gesamte Team und darüber hinaus. Das beinhaltet auch Aspekte wie plausibles und hilfreiches Auskommentieren des Codes als auch Clean Coding selbst. Um den Überblick nicht zu verlieren, empfehlen wir den Einsatz von agilem Projektmanagement, alleine wegen der Unvorhersehbarkeit eines ML Projekts und dem iterativem Vorgehen. Es hilft dabei, dass Aufgaben und Folgeschritte klar kommuniziert und organisiert sind.
Heutzutage werden in solchen Projekten Methoden der agilen Softwareentwicklung genutzt und etabliert. Die Nutzung von CI/CD Tools ist dabei kaum zu umgehen und ist Alltag für Kollegen und Kolleginnen aus dem digitalen Umfeld. CI/CD steht für Continuous Integration und Continous Delivery bzw. Deployment und hilft bei der Optimierung digitaler Prozesse. Häufig genutzte Tools in dem Zusammenhang sind beispielsweise Jenkins und Github. Eine etablierte CI/CD Pipeline hilft dem Unternehmen sich technisch optimal aufzustellen und Entscheidungswege zu verkürzen.
Vorteile von Machine Learning - Unser Fazit
Die Vorteile, ein Machine Learning Modell im Unternehmen zu implementieren und zu etablieren, lassen sich schnell zusammenfassen: Frühzeitige Erkennung von Mustern und Trends, Detektieren spezifischer Einflussvariablen und die Möglichkeit der Prozessoptimierung. Dadurch wird manuelle Arbeit ersetzt, wiederholende Aufgaben automatisiert und somit die Produktivität erhöht.
Die Erkenntnisse und Erfahrungen, die ein solches Projekt hervorbringen sind in unserer schnelllebigen digitalen Welt äußerst bedeutsam. Bereits der erste Schritt der Datenbeschaffung gibt Feedback zur Datenstruktur und ermöglicht neben der Datenprozessierung/-reinigung die Steigerung der Datenqualität.
Data Discovery sorgt dafür den Ball ins Rollen zu bringen und öffnet die Türen für weitere Projekte. Zu wissen, welche Informationen sich aus den Daten ableiten lassen hilft hierbei beachtlich. Und auch wenn das übergeordnete Ziel nicht aus den Augen verloren werden sollte, lohnt es sich Zwischenziele zu verfolgen und Nebenerfolge - wie das Kennenlernen eines neuen innovativen Tools - zu zelebrieren.
Wenn Sie Unterstützung bei der Planung und Ausführung von Machine Learning Projekten benötigen, sprechen Sie uns gerne an. Unsere Beratern besitzen unterschiedlichen Schwerpunkten und ergänzen ihr Projektteam mit den gewünschten Kompetenzen.


