






















Eine interessante Maßnahme zur Steigerung der ökologischen Nachhaltigkeit im Bereich der Künstlichen Intelligenz ist der Einsatz ressourcenschonender Algorithmen. Ein einfacher Ansatz beim Deep Learning ist es, die Anzahl der Parameter zweier Modelle zu vergleichen, um daraus Rückschlüsse auf einen möglichen Vorteil beim Energieverbrauch zu ziehen. Beim Vergleich zwischen klassischen Machine Learning Methoden sind Aussagen zum Energieverbrauch aufgrund der unterschiedlichen Funktionsprinzipien der Algorithmen nur schwer zu treffen. Hier kann ein praktischer Benchmark helfen, ein Gefühl für die Energieeffizienz zu bekommen.
In diesem Artikel zeigen wir Ihnen, wie Sie einen Benchmark vorbereiten und ausführen. Unsere Ergebnisse für verschiedene Klassifikationsalgorithmen helfen Ihnen dabei, den Energieverbrauch Ihrer Algorithmen in Zukunft besser einzuschätzen.
Vorbereitung des Benchmarks
Grundsätzlich ist der Energieverbrauch der Algorithmen abhängig von einer Reihe von Faktoren:
- die verwendete Programmiersprache
- die Implementierung des Algorithmus
- die gewählten Hyperparameter
- die eingesetzte Hardware
- die genutzte Datenbasis
Bei der Planung eines Benchmarks muss deshalb überlegt werden, welche Einflussfaktoren konstant gehalten werden sollen und wo sogar verallgemeinerte Aussagen über den Energieverbrauch des Modelltyps möglich sein sollen.
Die Wahl der Datenbasis hat einen Einfluss, da Algorithmen unterschiedlich empfindlich auf die Menge der Daten und Arten der Features reagieren. Einen speziellen Benchmark für Ihren Business Case erhalten Sie mit einem Datenauszug des entsprechenden Anwendungsfalls. Falls Sie hier verallgemeinern wollen, können mehrere generische Datensätze zum Einsatz kommen. Im UCI Machine Learning Repository findet sich eine große Auswahl an Datensätzen für überwachtes und unüberwachtes Machine Learning.
Vorbereitung der Datenbasis
Wenn allein die Effizienz der Algorithmen gemessen werden soll, sollte die Datenvorbereitung für alle Algorithmen einheitlich im Vorfeld erfolgen. Hierzu gehört beispielsweise das Umwandeln von kategorischen Werten, das Ausfüllen von fehlenden Werten und die Standardisierung. Die Anzahl der Features und die Menge der Datenpunkte sollten für eine spätere Normierung als Metadaten erfasst werden.
Vorbereiten der Algorithmen
Bei der Auswahl der Lernalgorithmen sollte entschieden werden, welche Programmbibliothek verwendet wird und welche Hyperparameter als Konfiguration gesetzt werden. Oft reicht hier die Standardvariante eines Algorithmus, wenn es darum geht, die Modelltypen miteinander zu vergleichen. Bei Ensemblemethoden kann die Anzahl der eingesetzten Modelle im Ensemble jedoch einen starken Einfluss auf die Performance der Modelle und deren Energieverbrauch haben. Ebenso erfolgt die Wahl des Kernels der Support Vector Machines über die Hyperparameter und beeinflusst die Ausführungszeit und somit den Energieverbrauch.
Green AI - Nachhaltig ausgerichtete
Künstliche Intelligenz für Unternehmen

Durchführung des Benchmarks
In der Ausführung des Benchmarks stehen die vorbereiteten Daten und die Instanzen der Algorithmen bereit. Damit der Energieverbrauch erfasst werden kann, können verschiedene Tools und Bibliotheken zum Einsatz kommen. Das Tool CodeCarbon ist hier besonders empfehlenswert, da die Reports direkt in einem Spreadsheet gespeichert oder über eine API gesammelt übertragen werden können. Die Implementierung ist über wenige Codezeilen realisiert. Eine getrennte Erfassung für das Training und die Prognose kann helfen, den Energieverbrauch von Beispielszenarien nach der voraussichtlichen Modellbenutzung abzuschätzen.
Der folgende Codeschnipsel zeigt einen bespielhaften Benchmark von mehreren Modellen über vorbereitete Datensätze.
|
for dataset in datasets: X = dataset[“X”] y = dataset[“y”]
for model_name in models: # init tracker tracker_train = EmissionsTracker(tracking_mode="process", log_level="error", project_name=f'{dataset[“name”]},{model_name}', output_file="train.csv") tracker_pred = EmissionsTracker(tracking_mode="process", log_level="error", project_name=f'{dataset[“name”]},{model_name}', output_file="pred.csv") model = models[model_name] # tracker model training tracker_train.start() model.fit(X,y) emissions = tracker_train.stop() # tracker prediction tracker_pred.start() model.predict(X); emissions = tracker_pred.stop() |
Auswertung des Benchmarks
Bei der Auswertung des Benchmarks werden die Ergebnisse für die Kommunikation im Projektmeeting oder zur Verwendung in der Modellentwicklung visualisiert. Wird mit verschiedenen Datensätzen gearbeitet, sollte der Energieverbrauch über die Featureanzahl und die Anzahl der Datenpunkte normiert werden. Da die Unterschiede über mehrere Größenordnung gehen, bietet sich das Verwenden einer logarithmierten Achse an.
Je nachdem wie es um das Statistikwissen des Beteiligten bestellt ist, können Boxplots einen schnellen Überblick über die Varibilität des Energieverbrauches geben oder einfache Balkendiagramme die Aussagen auf das Wesentliche reduzieren.
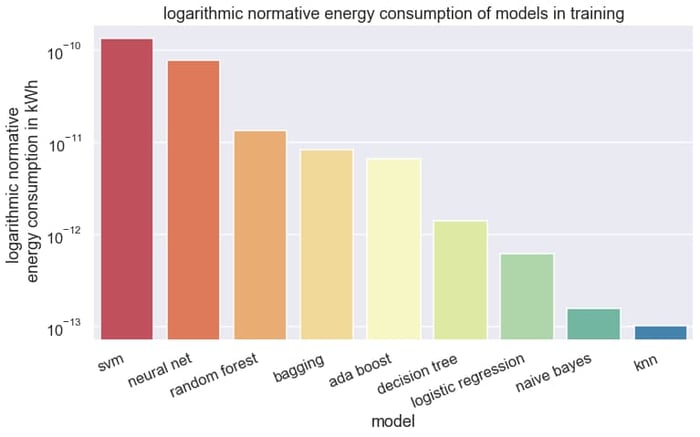
In unserem Benchmark von neun Klassifikationsalgorithmen über sechs Datensätze mit geschäftlichem Kontext wurde der Energieverbrauch des Trainings und der Prognose erfasst.
Im Training sind einfache Methoden wie die K-Nearest-Neighbor (KNN) Methode und Naive Bayes sehr sparsam. Die Ensemblemethoden Adaboost, Decision Tree Bagging und Random Forest sind trotz Einsatz mehrere Modelle sparsamer als ein neuronales Netz oder die Support Vector Machines. Das neuronale Netz mit einer versteckten Schicht verbraucht hier im Schnitt 1390-mal mehr Energie als die KNN Methode. Ein Blick auf das Ranking lohnt sich bei der Modellauswahl.
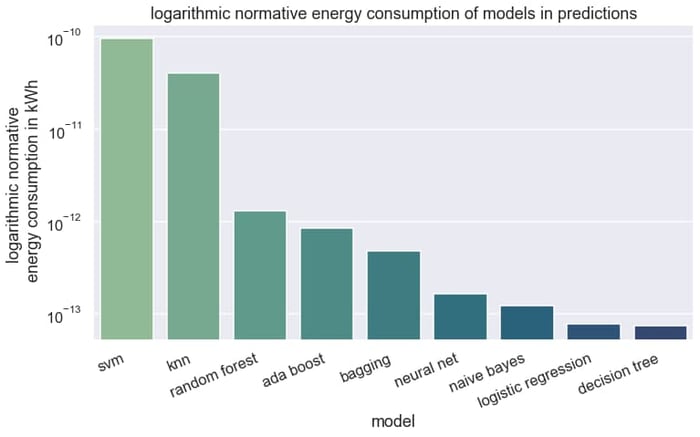
Für Unternehmen ist jedoch die Anwendung eines Models entscheidender, da dieser Prozess in der Praxis deutlich häufiger abläuft als das (Neu)training des Modells. Laut Angaben von AWS (Amazon Web Services) und Azure nimmt die Anwendung der Modelle beispielsweise in Form einer Prognose rund 90 % des Gesamtenergieverbrauchs ein. Die Methode KNN, welche im Training lediglich die Datenpunkte abspeichert und damit besonders gut abschneidet, hat in der Prognose fast den höchsten Energieverbrauch.
Zusammenfassend bietet ein Benchmark über den Energieverbrauch von Modellen den Entwickelnden ein gutes Hilfsmittel bei Auswahl der Modelle, sofern die Nachhaltigkeit der KI-Anwendungen gesteigert werden soll oder aus ökonomischen Gründen die Kosten der Modellausführung gesenkt werden sollen. Bei der Planung eines Benchmarks müssen Faktoren wie die Hardware, die Datenvorbereitung und die Modellkonfiguration beachtet werden.
Haben Sie weitere Fragen zu Green AI und zur nachhaltigen Gestaltung Ihres Data Science Bereichs? Wir beraten Sie gerne über mögliche Schritte und unterstützen Sie bei der Umsetzung. Bitte kontaktieren Sie uns.


