






















Durch die fortschreitende Verbreitung von Künstlicher Intelligenz über alle Unternehmensebenen hinweg und das steigende Vertrauen in die auf Statistik basierenden Modellierungen, geht der Trend dahin, die KI-Modellierung näher an die tatsächlichen Endnutzer zu bringen. Viele Datenanalyseplattformen bieten den Nutzern und Nutzerinnen einfache Funktionen, um ohne Code ihre Analysen um Machine Learning Ansätze zu erweitern. Bei einer solchen Self-Service-KI ist der Data Science Fachbereich nur noch in der Bereitstellung von dynamischen Modellierungsframeworks und einer passenden Datenbasis eingebunden. Besonders wenn der Self-Service Gedanke um die Möglichkeit ergänzt wird, externe Daten hinzuzufügen, hält die Gestaltung einige Herausforderungen bereit.
In diesem Artikel stellen wir Ihnen vor, welche Ansätze es gibt, externe Daten für die Self-Service Analysen von Business Anwendern und Anwenderinnen bereitzustellen. In unserem Showcase zeigen wir Ihnen, wie externe Faktoren dynamisch in eine Zeitreihenanalysen integriert werden können.
Herausforderungen bei der Integration von externen Daten
Die Integration von externen Daten in Business Analysen ist heutzutage notwendig, da komplexere Fragestellungen längst nicht mehr mit rein internen Daten beantwortet werden können. In der herkömmlichen Machine Learning Modellierung werden die Datenquellen jedoch auf eine fest definierte Weise für den spezifischen Anwendungsfall eingebunden, was keine Flexibilität und nur eine begrenzte Übertragbarkeit bietet. Möchten Business Anwender und Anwenderinnen eine einfache Möglichkeit haben Daten zu Wetter, Wirtschaft, Umwelt und geographischen Gegebenheiten in ihre Problemanalysen zu integrieren ergeben sich neue Herausforderung an die technische Realisierung:
- Zugriffsbeschränkung der Datenquellen
- Sicherstellung der Datensicherheit
- Bereitstellung von unterschiedliche Datenformaten
- Ausreichende Datenqualität für die Verwendbarkeit
Für die Bewältigung der Herausforderungen gibt es eine Reihe an Tools, welche die externen Daten hin zu den Analysen leiten. Die Gestaltung ist dabei beliebig simpel oder komplex.
Reifegrade der Bereitstellung
Es gibt unterschiedliche Reifegrade, wie eine Bereitstellung von externen Daten für die Anwendung in Self-Service Modellierungen umgesetzt werden kann. Die Einstufung erfolgt über die abnehmende Verantwortung seitens Datenaufbereitung und Modellierungsgestaltung.
- Verfügbarkeit im eigenen Data Lake
- Einbindung in einen Feature Store
- Integration in eine dynamische Modellierung
In der folgenden Übersicht ist die Verantwortung des Business Users je Bereitstellung aufgeführt.
%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-2.png?width=600&name=2022-03-17%20(DE)%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-2.png)
Verteilung der Verantwortlichkeiten für Arbeitsschritte zwischen Self-Service NutzerInnen und Data Science/Engineering Teams.
Verfügbarkeit im eigenen Data Lake
Die simpelste Variante externe Daten verfügbar zu machen, besteht über einen Data Lake. Verknüpft mit einem Metadatenmanagement oder Datenkatalog finden sich wichtige Informationen über die Aktualität und Versionierung. Es werden zusätzlich Zugriffsrechte und Verschlüsselungen geregelt. Benutzer und Benutzerinnen müssen jedoch eine Strukturierung und Aufbereitung, sowie die Zusammenführung mit den eigentlichen Analysedaten selbst vornehmen.
Ein gutes Beispiel für diese Umsetzung ist das Datenmanagement Tool SAP Data Intelligence. Darin ist ein Data Lake mit umfangreichem Metadatenmangement integriert, welcher Anwender und Anwenderinnen bei der Umsetzung ihrer Analyseideen unterstützt. Datenpakete können einfach hochgeladen werden und für andere Benutzer veröffentlicht werden.
Je nach Aufteilung der Verantwortlichkeiten kann das Laden der Daten über das Data Engineering Team gesteuert und automatisiert werden oder über die Endanwender und Endanwenderinnen in Eigenregie passieren.
%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-3.png?width=700&name=2022-03-17%20(EN)%20Integration%20externe%20Faktoren%20Self-Service-KI%20%7C%20ML%20Blog-3.png)
Veröffentlichte Daten im Metadata Explorer von SAP Data Intelligence. Die Daten im csv-Format sind im integrierten Data Lake abgelegt.
Kurbeln Sie Ihr Business durch Künstliche Intelligenz und Machine Learning an - Laden Sie sich das Whitepaper herunter!

Einbindung im Feature Store
Soll die Verantwortung für die Gestaltung der Datenbasis weiter in Richtung Data Engineering Team und weg von dem Anwendern und Anwenderinnen gebracht werden, eignet sich der Einsatz eines Feature Stores.
Als zusätzliche Abstraktionsschicht zwischen Datenquellen und der KI-Modellierung werden die benötigten Daten in Form von Feature Groups bereitgestellt. Die Vorverarbeitung wird hier übernommen und ein Feature Register hilft beim Auffinden von passenden Einflussfaktoren. Insbesondere das Matching von Daten kann hier bereits mit Bordmitteln des Systems geschehen und die Weiterverarbeitung erleichtern. Beispiele für KI-Self-Service Plattformen mit integriertem Feature Store sind Amazon SageMaker, Azure Databricks oder das Hopsworks Machine Learning Framework.
In anderen Self-Service Plattformen ist unter Umständen kein expliziter Feature Store integriert. Jedoch lassen sich Validierungen und Transformationsregeln (inklusive Joins) auf den Daten anwenden und diese in abgewandelter Form bereitstellen. Im Sinne geteilter Verantwortung für den Prozess bildet diese Variante einen Mittelweg zwischen der reinen Bereitstellung und der Zentralisierung im Feature Store.
Integration in eine dynamische Modellierung
Besonders in Anbetracht der Entwicklung eines internen Angebotes für Self-Service-KI ist die Bereitstellung der externen Faktoren als verwendbare Daten keine vollständige Lösung. Der Schritt der Modellierung muss durch eine Parametrisierung und Automatisierung ergänzt werden.
Die Modellierung wird in der Regel dynamisch über eine REST-Schnittstelle gesteuert, welche ein einfaches Einbinden in gängige BI-Tools ermöglicht. Neben der Verfügbarkeit von wählbaren externen Faktoren können auch die vorhanden Funktionen erweitert werden und neue Modelltypen eingebunden werden.
Die Datenbasis und die Endanwender und Endanwenderinnen sind strikt getrennt. Die Beschränkung des Zugriffs führt zu Standardisierung und mehr Datensicherheit durch eine zentrale Steuerung. Die verlorene Flexibilität kann meist durch einen gezielten Entwurf der Modellierungsoptionen nach erstellter Spezifikation aufgefangen werden.
Die Möglichkeiten dieser Variante lassen sich an einem praxisnahen Anwendungsbeispiel zur dynamischen Erzeugung von Zeitreihenanalysen gut erläutern.
Anwendungsidee: Automatisierte Zeitreihe mit einer dynamischen Auswahl von Einflussfaktoren
Zeitreihenanalysen sind ausgezeichnet automatisierbar und auf eine Reihe von Problemen anwendbar. Während im herkömmlichen Sinne nur ein Wert und seine zeitliche Entwicklung inklusive Trends und Saisonalitäten betrachtet wird, lassen diese sich um externe Faktoren ergänzen. Besonders wenn es um Umsatzzahlen geht, bringt die Analyse von Einflussfaktoren interessante Kenntnisse hervor. Gleichermaßen ist die produktspezifische Analyse aufgrund der großen Anzahl an Produkten möglichst dynamisch zu kreieren.
Wie lässt sich dies in einem System umsetzen? Mehrere Komponenten spielen hier zusammen:
- Interne Daten
Die Zeitreihendaten der Produkte müssen bereinigt vorliegen. Hier kann auch eine Auswahl der Granularität (monatliche vs. tägliche Werte) für den Business Anwender interessant sein.
- Externe Daten
Die Einflussfaktoren müssen im Unternehmen bereit liegen oder über eine Daten-API schnell bezogen werden. Wird eine API verwendet, ist das entsprechende Monitoring der Kosten und der Benutzung ebenfalls in das System zu integrieren. Das Matching passend zur Granularität der internen Daten muss ebenfalls geplant werden.
- Dynamische Modellierung
Die Zeitreihendaten der Produkte müssen bereinigt vorliegen. Hier kann auch eine Auswahl der Granularität (monatliche vs. tägliche Werte) für den Business Anwender interessant sein.
Die Modellierung sollte parametrisiert sein. Die Produktauswahl, die Modellauswahl und die ausgewählten Einflussfaktoren werden erst bei der Ausführung der Analyse festgelegt. Je nach Wunsch können auch optionale Vorbereitungsschritte und Feature Engineering parametrisiert oder automatisiert werden.
- Orchestrierung des Trainings
Die Ausführung der Modellierung und das Rückschreiben der Ergebnisse kann bequem über ein Workflowmanagement-Tool wie Apache Airflow ausgeführt werden, insofern dieses eine Parametrisierung unterstützt. Dort wird die Ausführung in Containern organisiert und passend skaliert.
- Front-End für Benutzereingaben
Eine einfache Benutzeroberfläche ermöglicht es dem Anwender und der Anwenderin die Analyse nach Bedarf zu starten und Ergebnisse auszuwerten. Webbasierte Front-Ends lassen sich als iFrame leicht in andere Anwendungen wie NextTables integrieren. Zudem bieten BI-Plattformen wie Tableau, SAP Analytics Cloud oder Power BI in der Regel die Option, eigene Verarbeitungslogiken per REST Schnittstelle mit wenig oder ohne Programmieraufwand in Dashboards einzubinden.
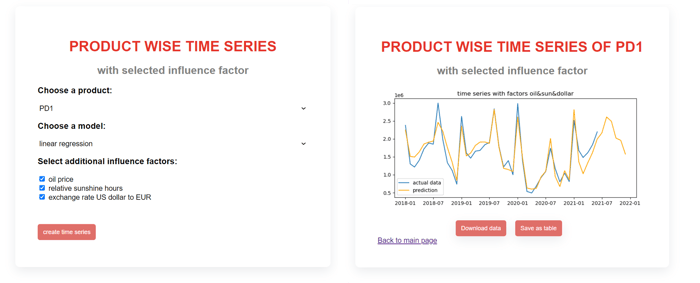
In einem einfachen Frontend sind Funktionen zur Produktauswahl, Modellauswahl und zur Einbindung von zusätzlichen Einflussfaktoren hinterlegt. Eine Darstellung der Ergebnisse kann auch hier oder in verbundenen BI-Tools erfolgen.
Selbstverständlich endet der Anwendungsfall nicht mit dem Anzeigen eines Ergebnisses. Die Daten selbst können in Planung Szenarien verwendet werden oder ein nachgelagertes Reporting evaluiert den jeweiligen Einfluss der Faktoren mit ausgewählten Kennzahlen. Eine treffende Modellierung kann auch für Prognosezwecke genutzt werden.
Self-Service Analytics - Unser Fazit
Insgesamt sind externe Daten eine umfangreiche Möglichkeit die Performance von Modellen zu verbessern. Die Bereitstellung für Business Anwender in Self-Service-KI Anwendungen kann auf verschiedenen Leveln erfolgen. Das Hinzunehmen von externen Faktoren ist insbesondere für Umsatzprognosen gut automatisierbar und ermöglicht passgenaue Analysen auch bei einer großen Produktpalette.
Benötigen Sie Unterstützung bei dem Einbinden von externen Daten in Ihre Machine Learning Workflows? Sprechen Sie uns gerne an. Wir helfen Ihnen in allen Projektphasen vom Systementwurf bis zur benutzerzentrierten Umsetzung weiter.


