






















Bevor ein Machine Learning-Modell einen kontinuierlichen geschäftlichen Mehrwert bietet, muss es zunächst die Hürde der praktischen Implementierung überwinden. Dabei sollen neben der Prognose auch andere Teile des Machine Learning-Workflows von der Datenvorbereitung bis zur Bereitstellung des trainierten Modells automatisiert ablaufen, um das Modell stets aktuell zu halten. Für das Workflowmanagement, also die Verwaltung, Planung und Ausführung der Aufgaben im Workflow, sind aus technischer Sicht viele Optionen verfügbar. Neben den verbreiteten Cronjobs steht auch die Workflowmanagement-Plattform Apache Airflow hoch im Kurs. In diesem Artikel erklären wir Ihnen, wie Airflow den Herausforderungen von Machine Learning-Workflows optimal begegnet und präsentieren Ihnen eine Architekturvariante für kleine Machine Learning (ML) -Teams.
Was ist Apache Airflow?
In Airflow werden die Workflows als Python-Skripte definiert, geplant und ausgeführt. Abhängigkeiten zwischen den Aufgaben und somit komplexe Workflows sind schnell und effizient abbildbar. Die funktionsreiche Weboberfläche verschafft eine gute Übersicht über den Status der Workflowläufe und beschleunigt die Fehlerbehebung ungemein. Das Framework ist zudem open-source und kostenlos nutzbar.
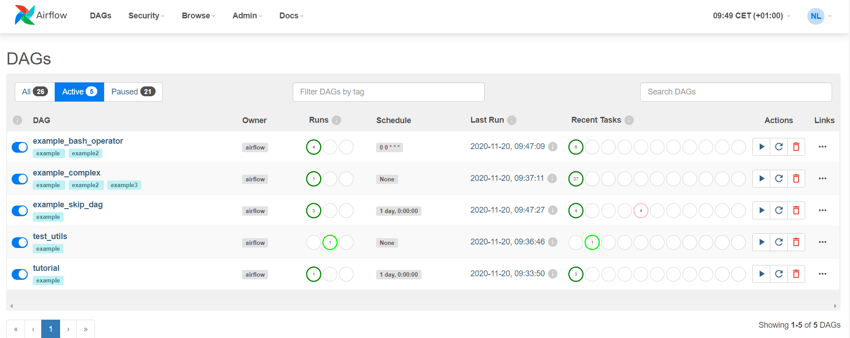
Weboberfläche Apache Airflow. Der Status der Workflowläufe ist links sichtbar ( Runs). Die Stati der Aufgaben des letzten Workflows ist rechts zu sehen (Recent Tasks).
Airflow übernimmt für Machine Learning-Workflows folgende Aufgaben:
- Definieren, Ausführen und Überwachen von Workflows
- Orchestrierung von Drittsystemen zur Ausführung von Aufgaben
- Bereitstellen einer Web-Oberfläche für eine ausgezeichnete Übersicht und umfassende Verwaltungsfunktionen
Falls Sie die zugrundeliegenden Konzepte und die Komponenten von Apache Airflow gerne näher kennenlernen wollen, empfehlen wir Ihnen die Lektüre unseres Whitepapers "Effektives Workflowmanagement mit Apache Airflow 2.0". Dort werden die Grundideen ausführlich erklärt und Sie erhalten praktische Anwendungsideen bezüglich der neuen Funktionen im Major Release.
Optimieren Sie Ihr Workflowmanagement
mit Apache Airflow

Warum ist Airflow besonders für Machine Learning geeignet?
Machine Learning Workflows sind in der Regel durch die Abhängigkeiten zwischen den einzelnen Schritten und durch die Vielzahl an beteiligten Datenquellen komplexer als ETL Workflows. Zusätzlich haben die verschiedene Modelle nicht selten unterschiedliche Anforderungen an die Hardware (CPU vs. GPU). Das einfache Starten der Workflows mit Cronjobs stößt deshalb oft an seine Grenzen und ist durch die fehlende Abhängigkeit zwischen den einzelnen Aufgaben fehleranfällig. Wegen der einfachen Bedienbarkeit und Implementierung setzt sich schließlich Apache Airflow für das Workflowmanagement von Machine Learning-Anwendungen durch.
Machine Learning-Workflows in Airflow
Ein Machine Learning-Workflow beinhaltet verschiedene Aufgabenpakete, die sich in die Datenvorbereitung, das Modelltraining und -evaluation und die Bereitstellung des Modells gliedern. Airflow übernimmt dabei die Ausführung der einzelnen Workflow-Läufe. Je nach Belieben kann ein Workflow mit integrierten Schritten erstellt werden (siehe Abbildung) oder es können separate Workflows für die Unterpunkte definiert werden, falls einzelne Komponenten (z. B. die Datenvorbereitung) einem eigenen zeitlichen Intervall folgen sollen.

Simpler Machine Learning-Workflow mit integrierten Schritten
- Datenvorbereitung
Im Zuge der Vorbereitung für das Training finden verschiedene ETL-Prozesse statt. Innerhalb des Workflows können wichtige Informationen über den Datenumfang und die statistischen Eigenschaften der Features ausgegeben werden. Diese helfen dabei, potentielle Fehlerquellen aufzudecken.
- Modelltraining und -evaluation
Damit das Modell sich auch an eine neue Datenlage anpassen kann, empfiehlt sich ein regelmäßiges Training auf aktuellen Daten. Dieses kann zeitlich gestartet werden oder per REST API in Gang gesetzt werden, falls das produktive Modell eine bestimmte Fehlerschranke erreicht.
- Bereitstellung des Modells
Je nachdem ob das Modell als Service innerhalb einer Applikation verwendet wird oder als Erzeuger von Prognosetabellen eingesetzt wird, unterscheidet sich die Bereitstellung. Soll das Modell regelmäßig Prognosen liefern, kann selbst der Prognoseschritt von Airflow aus zeitlich gesteuert werden.
Machine Learning-Architektur für den Einstieg
Die Airflow Installation ist flexibel konfigurierbar und ermöglicht eine Skalierung entsprechend der Bedürfnisse. Diese wird vorrangig durch die Auswahl des passenden Executer umgesetzt. Im Folgenden ist eine Einsteiger-Architektur erläutert. Diese erfüllt die Anforderungen kleiner Teams, die Workflows auf einem einzigen Server ausführen möchten. Neben Airflow spielen Git für die Versionskontrolle und Anaconda für die Isolation eine Rolle. Für eine schnelle, sichere Verbindung zur SAP HANA kann beispielsweise das NextLytics-Software-Development-Kit (NLY-SDK) verwendet werden, welches wir Ihnen gerne auf Anfrage näher vorstellen.

ML-Architektur mit Airflow (Scheduling), Git (Versionskontrolle), Anaconda (Isolation) und einem Airflow DAG für das Deployment und Anbindung zu Datenbanken und Filesystemen
- Single-Node Architektur Airflow
Die einzelnen Aufgaben des Workflows werden lokal auf dem System ausgeführt, auf dem auch Airflow installiert ist. Hierbei ist eine parallele Ausführung der Aufgaben durch den LocalExecuter gegeben. Dabei gibt es mehrere Worker-Instanzen des Webservers. Seit Airflow 2.0 ist auch die Verwendung von mehreren Scheduler-Instanzen möglich.
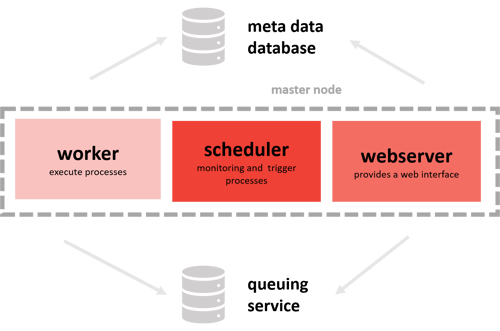
In der Single Node Architektur werden die Aufgaben per Worker, der Webserver und der Scheduler auf dem Server ausgeführt
- Anaconda Environments
Werden die Machine Learning-Workflows lokal auf einem Server ausgeführt, muss die Architektur eine Möglichkeit bieten, die unterschiedlichen softwareseitigen Anforderungen der Modelle umzusetzen. Dies ist ein besonders wichtiger Punkt in Machine Learning-Anwendungen, da häufig spezifische Versionen der einzelnen Programmbibliotheken benötigt werden. Dafür sind virtuelle Umgebungen geeignet. Hierbei kommen häufig die Conda Environments zum Einsatz. Die Skripte werden dann über den Interpreter der gewünschten Umgebung ausgeführt. - Datenaustausch
Airflow ist konzeptionell nicht für “echte” Daten-Pipelines ausgelegt. Die anfallenden Daten müssen zwischen den Schritten abgelegt werden. Das kann beispielsweise auf dem Server, in einer Datenbank oder in der Cloud erfolgen. Airflow bietet mit XCOM eine Kommunikationsmöglichkeit zwischen den verschiedenen Aufgaben. Diese kann über die TaskflowAPI leicht definiert werden.
- Deployment der Workflow-Dateien
Die Workflows werden als Python-Dateien gestaltet. Ist ein Workflow produktionsreif, wird er in einem Git Repository abgelegt. Von dort aus wird er mittels Pull-Request auf den Server übertragen. Dabei wird der regelmäßige Pull-Request über einen eigenen Airflow-DAG gesteuert. Eine Verbesserung des Continuous Deployment mit z. B. vorgeschalteten, automatisierten Tests kann mit Jenkins, Drone oder GitHub Actions realisiert werden.
Selbstverständlich eignet sich die vorgestellte Architektur nicht für alle Anwendungsszenarien. Steigt die Anzahl der Workflows rapide an, ist die Architektur den Anforderungen nicht mehr gewachsen. Glücklicherweise lässt sich Airflow mit Kubernetes, Mesos oder Dask effizient skalieren. Der Betrieb auf verteilten Systemen sollte sorgfältig geplant werden.
Wir stehen Ihnen für Ihre End-to-End Machine Learning-Projekte und/oder zur Bewertung Ihres Status Quo gerne als kompetenter Projektpartner zur Seite. Wir helfen Ihnen dabei, robuste und skalierbare Machine Learning-Workflows auf Apache Airflow zu realisieren. Sprechen Sie uns jederzeit an!


