






















In Fachkreisen hat sich mittlerweile etabliert, dass Airflow eines der modernsten Werkzeuge für die Planung und Überwachung von Arbeitsabläufen innerhalb eines einheitlichen Framework ist. Airflow ermöglicht es uns, komplexe Abhängigkeiten zwischen verschiedenen Aufgaben (Tasks) innerhalb von DAGs (direktionale azyklische Graphen) zu definieren, wobei die Ausführung von DAGs bis vor kurzem ähnlich wie bei Cron nur zeitbasiert möglich war. Die datengesteuerte Auftragsplanung wurde mit Version 2.4 neu in Airflow eingeführt und ermöglicht es Entwicklern, eine Producer-Consumer-Beziehung zwischen DAGs zu definieren. Ein DAG kann nun unabhängig von einem vordefinierten Zeitplan durch eine auf einem Datensatz operierende Aufgabe ausgelöst werden, sobald dieser Datensatz aktualisiert wird.
Nehmen wir beispielsweise an, es gibt einen Task, der Wechselkurse in eine Datenbanktabelle importiert, und einen weiteren DAG, der eine Transformation auf diesen Daten durchführt. Letzterer soll sofort nach Abschluss des Datenbankimports ausgelöst werden. Wir werden dieses Szenario im Detail durchgehen und einige konkrete Codebeispiele liefern.
Vorteile der datengesteuerten Planung
Die zeitbasierte Planung eines Workflows funktioniert gut, wenn im Voraus klar ist, wann jeder Prozess ausgeführt werden soll. Dies kann zu Problemen führen, sobald Abhängigkeiten zwischen DAGs definiert werden müssen. Betrachten wir das folgende Szenario: Data Engineering-Team A führt eine Vorverarbeitungs-Pipeline aus, die regelmäßig einen Datensatz erstellt/aktualisiert. Dabei könnte es sich um eine einfache Textdatei, einen Datenbankeintrag oder eine andere beliebige Ressource handeln. Data Analysis-Team B führt eine Pipeline aus, welche den Datensatz liest und auf dessen Basis Analysen und Berechnungen durchführt. Team B möchte so schnell wie möglich über die Verfügbarkeit des neuen Datensatzes informiert werden, um die Ausfallzeit zwischen zwei Pipelineausführungen zu minimieren. Dies kann durch die Verwendung eines datengesteuerten Planungsmechanismus erreicht werden, bei dem der Verbraucher benachrichtigt wird, sobald eine Änderung vom Ersteller veröffentlicht wird und seine Pipeline-Ausführung sofort beginnt. Dies führt zu einer schnelleren und robusteren Pipeline-übergreifenden Kommunikation. Stakeholder, die Just-in-Time-Daten für ihre Berichte und Dashboards benötigen, erhalten somit immer die aktuellsten Daten so schnell wie möglich.
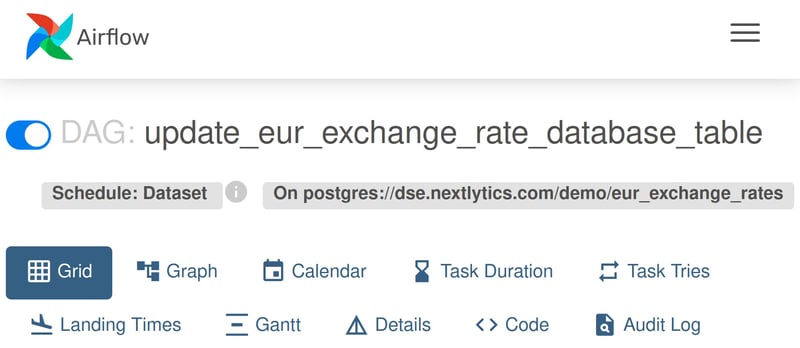
“update_eur_exchange_rate_database_table” DAG ist basierend auf einer Datensatzaktualisierung eingeplant.
Was ist ein Datensatz in Airflow?
Ein Datensatz in Airflow (Airflow Dataset) steht für eine logische Gruppierung von Daten. Datensätze können von vorgelagerten "Prodcuer"-Aufgaben aktualisiert werden, während Dataset-Aktualisierungen zur Planung von nachgelagerten "Consumer"-DAGs beitragen. Das bedeutet, dass ein DAG nur dann ausgeführt wird, sobald ein von diesem abhängiger Datensatz aktualisiert wird. Airflow macht keine Annahmen über den Inhalt oder den Speicherort des Datensatzes, was bedeutet, dass es sich hierbei um eine einfache, lokal gespeicherte Textdatei, eine Datenbanktabelle, einen Azure-Storage-Blob etc. handeln kann. Der Datensatz wird durch eine URI (Uniform Resource Identifier) identifiziert, d. h. zwei Datensatzobjekte mit derselben URI werden als auf dieselbe Ressource bezogen betrachtet. Wenn ein DAG von mehreren Datensätzen abhängt, beginnt die Ausführung, wenn jeder Datensatz mindestens einmal aktualisiert wurde. Hierbei ist zu beachten, dass der Datensatz als aktualisiert gilt, sobald die für die Aktualisierung verantwortliche Aufgabe erfolgreich abgeschlossen wurde. Airflow kann nicht feststellen, ob der Datensatz tatsächlich aktualisiert wurde, weswegen es in der Verantwortlichkeit der Entwickelnden liegt sicherzustellen, dass die Aktualisierung abgeschlossen ist. Mit anderen Worten: Es findet keine Abfrage statt, um sicherzustellen, dass die Ressource tatsächlich aktualisiert wurde.
Praxisbeispiele
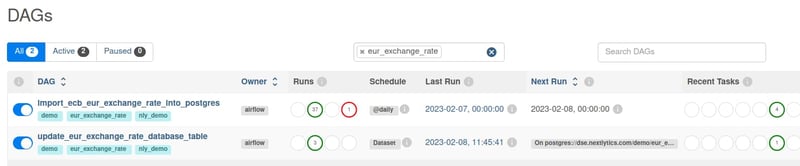
Die nächste Ausführung des DAG “update_eur_exchange_rate_database_table” wird durch
die Aktualisierung einer bestimmten Ressource bestimmt.
Nehmen wir folgendes Beispiel zur Veranschaulichung der Verwendung der neuen Funktion zur datengesteuerten Aufgabenplanung. Der DAG "import_ecb_eur_exchange_rate_into_postgres" ist dafür verantwortlich, die aktuellen Wechselkurse für den Euro abzurufen und in eine Postgres-Datenbank einzufügen. Der DAG "update_eur_exchange_rate_database_table" soll ausgeführt werden, sobald eine Aktualisierung verfügbar ist.
Zuerst wird der “Producer”-DAG "import_ecb_eur_exchange_rate_into_postgres" definiert:
import io
import pandas as pd
import pendulum
import requests
import sqlalchemy
from airflow import Dataset
from airflow.decorators import task, dag
from airflow.hooks.base import BaseHook
db_conn = BaseHook.get_connection("pg_default")
engine = sqlalchemy.create_engine(
f"postgresql+psycopg2://{db_conn.login}:{db_conn.password}@{db_conn.host}:{db_conn.port}/{db_conn.schema}")
@dag(
schedule_interval="@daily",
start_date=pendulum.datetime(2023, 1, 1, tz="UTC"),
catchup=True,
)
def import_ecb_eur_exchange_rate_into_postgres():
@task
def get_ecb_exchange_rate_data(**kwargs) -> str:
base_url = "https://sdw-wsrest.ecb.europa.eu/service/data"
flow_ref = "EXR"
key = "D..EUR.SP00.A"
logical_date = kwargs["ds"]
parameters = {
"startPeriod": logical_date,
"endPeriod": logical_date,
"format": "csvdata",
}
request_url = f"{base_url}/{flow_ref}/{key}"
response = requests.get(request_url, params=parameters)
return pd.read_csv(io.StringIO(response.text)).to_json()
@task(outlets=[Dataset("postgres://dse.nextlytics.com/demo/eur_exchange_rates")])
def import_exchange_rate_data_into_postgres(json_data: str, table: str):
loadtime = pendulum.now().isoformat()
df_source = pd.read_json(json_data)
df_db = pd.DataFrame().assign(
exchange_rate_date=df_source["TIME_PERIOD"],
currency=df_source["CURRENCY"],
currency_name=df_source["TITLE"].str.replace("/Euro", ""),
rate=df_source["OBS_VALUE"],
_loadtime=loadtime)
with engine.connect() as con:
df_db.to_sql(name=table, con=con, if_exists="append", index=False)
json_data = get_ecb_exchange_rate_data()
import_exchange_rate_data_into_postgres(json_data, table='eur_exchange_rates')
dag = import_ecb_eur_exchange_rate_into_postgres()
Die Aufgabe "import_exchange_rate_data_into_postgres" definiert eine Liste von Datensatzobjekten als "outlets", d. h. Datensätze, die von dieser Aufgabe erzeugt oder aktualisiert werden. In diesem Fall fügt die Aufgabe einige neue Einträge in eine Datenbanktabelle ein.
Optimieren Sie Ihr Workflowmanagement
mit Apache Airflow!

Der “Consumer”-DAG "update_eur_exchange_rate_database_table" ist wie folgt definiert und hat die Aufgabe, nur die neuesten Wechselkursdaten in eine separate Tabelle einzufügen, sobald eine neue Datenlieferung verfügbar ist:
import pendulum
import sqlalchemy
from airflow import Dataset
from airflow.decorators import task, dag
from airflow.hooks.base import BaseHook
db_conn = BaseHook.get_connection("pg_default")
engine = sqlalchemy.create_engine(
f"postgresql+psycopg2://{db_conn.login}:{db_conn.password}@{db_conn.host}:{db_conn.port}/{db_conn.schema}")
@dag(
schedule=[Dataset("postgres://dse.nextlytics.com/demo/eur_exchange_rates")],
start_date=pendulum.datetime(2023, 1, 1, tz="UTC"),
catchup=False,
)
def update_eur_exchange_rate_database_table():
@task
def update_table(**kwargs):
with engine.begin() as con:
backup_table = "ALTER TABLE IF EXISTS report_current_eur_exchange_rates RENAME TO report_current_eur_exchange_rates_bak"
con.execute(backup_table)
update_table = """
select
distinct eer.currency,
eer.currency_name,
(select rate from eur_exchange_rates eer2 where eer2.currency=eer.currency
order by eer2.exchange_rate_date desc limit 1),
now() as update_timestamp
into report_current_eur_exchange_rates
from eur_exchange_rates eer order by currency asc;"""
con.execute(update_table)
remove_backup = "drop table if exists report_current_eur_exchange_rates_bak"
con.execute(remove_backup)
update_table()
dag = update_eur_exchange_rate_database_table()
Der "Consumer"-DAG wird auf der Grundlage eines Datensatzes geplant, der in diesem Fall die von unserem Beispiel erzeugte URI teilt. Hierbei ist zu beachten, dass die für die Definition der Abhängigkeiten verwendeten Datensatzobjekte unterschiedlich sind, sich aber auf dieselbe Ressource beziehen. Der DAG wird ausgelöst, sobald die Aufgabe "import_exchange_rate_data_into_postgres" des “Producer” erfolgreich ist, sodass zwischen den beiden DAG-Ausführungen keine Ausfallzeit entsteht.
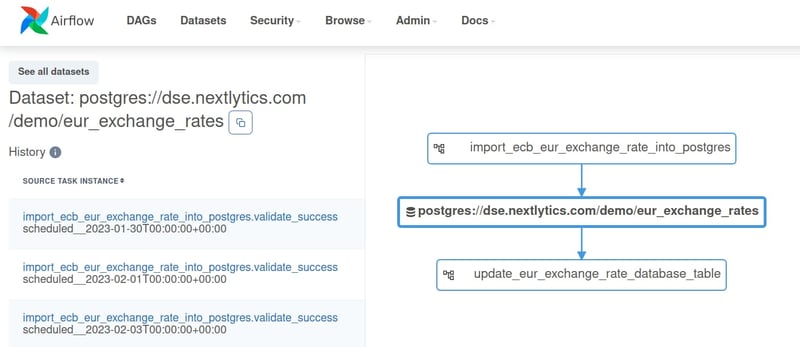
Visuelle Darstellung der Beziehungen zwischen den DAGs. Beachten Sie die Dataset-Ressource in der Mitte.
Diese neue Funktion bietet mehr Flexibilität bei der Planung von miteinander verbundenen DAGs, aber es gibt auch einige Fallstricke zu vermeiden. Es ist zum Beispiel möglich, eine Aufgabe zu erstellen, die eine Ressource aktualisieren soll, ohne dass überhaupt mit der Ressource interagiert wird. Airflow lässt dies zu, weil es im Ermessen des Entwickelnden liegt zu entscheiden, was eine Aktualisierung ist. Airflow betrachtet einen Datensatz als aktualisiert, wenn die Aufgabe, die zur Aktualisierung zugewiesen wurde, erfolgreich ausgeführt wird, unabhängig von der Implementierung der Aufgabe. Die Airflow-Dataset API bewahrt die Designentscheidung, die Workflow-Prozesslogik von den verarbeiteten Daten zu trennen und ermöglicht gleichzeitig eine engere Kopplung mit weniger benutzerdefiniertem Code.
Jahrelange Diskussionen und Entwicklungen haben schließlich zu dem oben beschriebenen neuen Airflow Dataset-Konzept geführt. Die derzeitige Implementierung ist lediglich ein Wrapper um die eigentlichen Datenartefakte, der über die DAG-übergreifende Planung hinaus wenig Funktionalität bietet. Insbesondere gibt es noch keinen REST-API-Endpunkt, um einen Datensatz als extern aktualisiert zu markieren, was interessante systemübergreifende Integrationsszenarien eröffnen würde. Die Möglichkeit des Just-in-Time-Schedulings von DAGs ist nach wie vor eine äußerst wertvolle Ergänzung des ständig wachsenden Apache Airflow-Toolsets und bietet Data-Engineers eine weitere Möglichkeit, die Herausforderungen im Geschäftsalltag zu meistern.
Haben Sie noch Fragen oder Interesse an einem Austausch? Sprechen Sie uns gerne an. NextLytics steht Ihnen gerne als erfahrener Projektpartner zur Seite. Vereinbaren Sie ein erstes Gespräch mit unserem NextLytics Data Science and Engineering Team. Wir sind gespannt auf Ihre Anwendungsfälle und entwickeln mit Ihnen Lösungen, die für Ihre spezifischen Anforderungen optimiert sind.


