ETL - Dieses Akronym beschreibt wie kein Zweites den immensen Aufwand, der seit der Entstehung von Data Warehouses und Business Intelligence allerorten betrieben werden musste, um Daten aus ihren Quellsystemen in das Analysesystem zu überführen. Extract, Transform, Load sind dabei die namensgebenden logischen Schritte solcher Prozesse, die lange auch in dieser Reihenfolge gedacht und implementiert worden sind. Seit einigen Jahren aber hat sich der Trend hin zu dem augenscheinlich nur leicht abgeänderten Paradigma “ELT” gewendet, Extract, Load, Transform. Was steckt dahinter, welche Vorteile verspricht der neue Ansatz und wie kann Apache Airflow ELT-Mechaniken für Ihre Datenverarbeitung ermöglichen? Diese Fragen wollen wir heute beantworten.
ETL und ELT - Was ist der Unterschied?
Klassische Data Pipelines, oft auch direkt als “ETL-Strecken” bezeichnet, sind darauf ausgelegt, eine Datenquelle mit einem Zielsystem zu verknüpfen und im Laufe des Transportprozesses genau das benötigte Zielformat herzustellen. Ganze Datenintegrationsplattformen und Systemlandschaften sind rund um dieses einfache Prinzip über die Jahre entstanden und haben sich als das verbindende Element zwischen operativen Systemen und analytischem Data Warehouse in vielen Unternehmen etabliert. Mit wachsender Zahl von Quellsystemen und neuen Anforderungen an die analytische Verwendung von Daten steigt die Zahl der benötigten ETL-Strecken exponentiell: Für jede Datenquelle müssen verschiedene Zielformate erzeugt werden und die Komplexität des Gesamtsystems explodiert. Da die Verarbeitung in einer eigens dafür vorgesehenen Systemkomponente ausgeführt wird, müssen entsprechende Ressourcen für diese vorgehalten werden (CPU und Arbeitsspeicher). Diese Bedarfe sind in der Regel für kurze Lastspitzen sehr hoch, liegen aber für einen Großteil der Zeit brach. Datenverarbeitung nach ETL-Schema wird somit zu einem teuren, ineffizienten Flaschenhals sowohl aus technischer als auch organisatorischer Sicht.
Der Paradigmenwechsel zum ELT-Schema setzt auf eine Verschiebung der Transformationslogik bis hin zur kompletten Virtualisierung dieses Schrittes. Aus jeder Datenquelle wird zunächst in ein einheitliches Speichersystem der Analyseplattform übertragen, bevor in dieser Plattform die verschiedenen benötigten Transformationen durchgeführt werden. In der einfachsten Form heißt das beispielsweise, dass Quelldaten unbereinigt in eine logische Zone der Warehouse-Datenbank geschrieben werden und anschließend über Views innerhalb dieser Datenbank für verschiedene Analysezwecke aufbereitet und verwertet werden. In der Cloud bzw. einer Data Lake oder Lakehouse Architektur, landen die Rohdaten im günstigen Object Storage, bevor sie weiterverarbeitet werden. Die Komplexität der Quelle-Senke-Verbindungen kann zumindest für die erste Phase somit auf eine lineare Abbildung reduziert werden. Durch die Verlagerung der ressourcen-hungrigen Transformationsschritte in ein ohnehin bestehendes, performantes System wie eine Datenbank bzw. eine Cloud-Plattform wird auch dieser Flaschenhals aufgelöst.
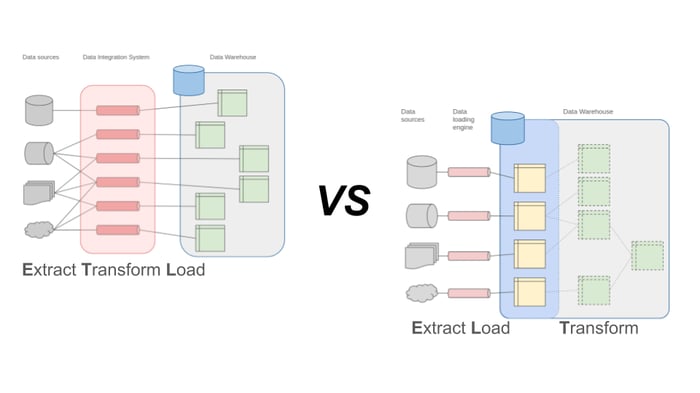
ELT-Prozesse im Data Warehouse
Ganz neu ist der ELT-Ansatz nicht und wird in großen Data Warehouse Plattformen und Enterprise Datenbanken mit entsprechenden Werkzeugen schon lange konzeptionell unterstützt. Aufwind hat das ELT Paradigma in den letzten Jahren vor allem mit der Entwicklung neuer Werkzeuge für das einheitliche Management von Datenmodellen gewonnen: Angeführt von dbt etablieren diese Tools eine einheitliche Schnittstelle für automatische oder virtuelle Transformationen von Daten, die einmal ins Warehouse geladen worden sind. Auf diese Weise sollen Effizienz und Ordnung in die komplexen Abbildungen im Data Warehouse gebracht werden.
Apache Airflow ist der Vorreiter moderner Open Source Workflow-Management Plattformen und hat in den letzten Jahren eine wichtige Rolle in der Weiterentwicklung und Optimierung von Data Engineering Prozessen gespielt. In Airflow werden Workflows als Programmcode in der Programmiersprache Python definiert. Das System ist aus diesem Grund für praktisch jeden Zweck nutzbar und beliebig erweiterbar, die Abläufe aufgrund starker Kopplung an ausgereifte Best Practices aus der Softwareentwicklung zu jedem Zeitpunkt nachvollziehbar. Aufgrund der skalierbaren und ausfallsicheren Systemarchitektur ist Airflow ein sehr robuster und zuverlässiger Taktgeber für zeitgesteuerte und automatisierte Abläufe. Als Open Source Plattform kann Airflow für vielfältige Aufgaben genutzt werden und bietet insbesondere für komplexe Datenströme sehr gute Steuerungsmöglichkeiten.
Im ELT Paradigma werden das initiale Laden von Daten in ein Speichersystem und die Transformation auf ein benötigtes Format also entkoppelt. Eine sequenzielle Verknüpfung und zuverlässige Ausführung der einzelnen Schritte wird allerdings weiterhin benötigt. Die Kombination von ELT Werkzeugen mit Apache Airflow ist hier offensichtlich sinnvoll. Wie diese Integration aussehen kann, schauen wir uns am Beispiel der folgenden Vertreter dieser Klasse von Tools einmal genauer an: Singer, Meltano, Airbyte und DLT.
Apache Airflow als Grundlage für ELT-Prozesslandschaften
Grundsätzlich bringen moderne ELT-Werkzeuge bis zu einem gewissen Grad eigene Ausführungs- und Workflow-Umgebungen mit. Ihre ausgewiesene Stärke sind diese Komponenten allerdings nicht, sodass oft sogar die Integration mit einem eigenständigen Orchestrator nahegelegt wird. Die Art der Integration mit Apache Airflow ähnelt sich dabei häufig: Die Tools erlauben die Definition von Ladevorgängen von unterstützten Quellsystemen hinein in bestimmte Zielsysteme über Konfigurationsparameter. Die Ausführung einer solchen Ladestrecke wird dann in der Regel über ein Command Line Interface (CLI) angestoßen. Alternativ bieten Sie ein vollwertiges grafisches Benutzerinterface und REST-basierte Programmierschnittstellen an.
Singer
Singer ist einer der Vorreiter im Feld der ELT-Tools und das Open Source Gerüst hinter dem Cloud-Dienstleister Stitch. Singer definiert ein JSON-basiertes Format für den Austausch von Daten zwischen beliebigen Quellen (“Taps”) und Senken (“Targets”), sofern entsprechende Interfaces existieren. Die implementierten Taps und Targets sowie das Singer Framework sind Python Code und können über die Paketverwaltung PyPI installiert werden. Konfiguration einer Ladestrecke erfolgt dann über CLI Befehle und YAML-Dateien. Die Ausführung einer Ladestrecke kann wieder per CLI gestartet werden. Um eine Apache Airflow ELT Infrastruktur mit Singer aufzubauen, müssen die erzeugten Konfigurationsdateien in entsprechenden Verzeichnissen für Airflow verfügbar gemacht werden und per BashOperator über das Singer-CLI ausgeführt werden.
Optimieren Sie Ihr Workflowmanagement
mit Apache Airflow!
Meltano
Meltano ist ein weiteres Open Source Projekt, dass sich die Singer Spezifikation von Taps und Targets zunutze gemacht hat, um eine noch umfangreichere Abdeckung hinsichtlich unterstützter Quellen und Senken zu erreichen. Meltano folgt auch konzeptionell weitgehender der gleichen Struktur und sieht die Definition von Ladestrecken über das eigene CLI vor. Sofern nicht das zugehörige Cloud-Produkt genutzt wird, können Meltano-Pipelines auch mit einem ad-hoc Airflow Scheduler ausgeführt oder direkt per CLI mit einer bestehenden Apache Airflow Instanz orchestriert werden. Faktisch erfolgt auch dies über die Bereitstellung von Konfigurationsdateien in entsprechenden Ordnern. Meltano erlaubt es, per CLI Airflow-kompatible Python-Definitionen für Ladestrecken zu erzeugen. Alternativ kann auch hier per Airflow BashOperator direkt über das Meltano CLI eine Strecke ausgelöst werden bzw. dieser Prozess in einem eigens erzeugten Docker Container ausgeführt werden.
DLT
Strukturell sehr ähnlich, aber auf einer völlig eigenständigen Python-Codebasis entwickelt, etabliert sich das DLT Projekt derzeit als weiterer Aspirant auf dem Markt der ELT-Tools. DLT steht für “data load tool” und beschreibt auch schon das primäre Ziel: generisches Laden von Daten aus verschiedenen Quellen ohne große Ambitionen, selbst als Plattform zu operieren. Auch DLT arbeitet mit eigenem CLI, über das Quelle und Senke konfiguriert werden. Anschließend lässt sich die Art und Weise der Übertragung granular in Python-Code einstellen und ausführen. Um eine DLT-Pipeline mit Airflow zu steuern, muss jedoch ebenfalls das Arbeitsverzeichnis samt Konfigurationsdateien synchronisiert und per CLI bzw. Python-Kommando ausgelöst werden.
Airbyte
Einen etwas anderen Weg geht das Airbyte Projekt, das auch in seiner Open Source Edition als vollwertige Plattform mit ausgereiftem User Interface daherkommt. Pipelines werden hier über Konfigurationsformulare im Browser zusammengestellt, können per Klick ausgeführt und granulare Log- und Metadaten eingesehen werden. Airbyte bringt sowohl ein eingebautes Scheduling-System für einfache zeitgesteuerte Sequenzen mit als auch eine REST-API mit allen Steuerbefehlen. Über diese API erfolgt auch die Integration mit Airflow, wobei sogar ein dedizierter Airbyte-Operator zur Verfügung steht. Airbyte-Ladestrecken können somit nativ in Workflows eingebunden werden, werden gestartet und ihr Erfolg über asynchrones Status-Monitoring in Airflow nachvollzogen.
ELT ohne zusätzliche Tools?
Die vorgestellten Werkzeuge legen allesamt den Fokus auf das initiale Laden von Daten in eine Warehouse-Infrastruktur. Als Senken werden dabei in der Regel alle gängigen relationalen Datenbankmanagementsysteme unterstützt, insbesondere aber auch die populären Cloud Data Warehouses oder Data Lake Storage Systeme. Singer, Meltano, DLT und Airbyte bieten für diesen Zweck eine einheitliche deklarative Sprache und ermöglichen mit verhältnismäßig geringem Aufwand die Definition und den Betrieb einer Vielzahl von Datenströmen.
Eine reine Python-Bibliothek mit diesem Einsatzzweck, die völlig ohne eigenes CLI genutzt und damit komplett nativ in ein Apache Airflow ELT Konzept eingebunden werden kann, hat sich aktuell leider noch nicht etabliert.
Um die Vorteile des ELT-Paradigmas zu genießen, ist grundsätzlich kein dediziertes Tool notwendig. Insbesondere für Warehouse-Architekturen, die inhouse betrieben werden und eine begrenzte Anzahl von Datenquellen anbinden, kann reiner Python-Code mit Airflow als Entwicklungsframework eine effiziente Alternative sein, wie wir am Beispiel von SAP Datenextraktionen bereits demonstriert haben. Im Anschluss an den Ladeprozess können über reine SQL-Templates ebenfalls nativ mit Airflow die entsprechenden Transformationen ausgeführt werden, ohne dass wiederum ein dediziertes Tool wie dbt eingesetzt werden muss. Mehrdimensionale Abhängigkeiten zwischen Ladestrecken und Transformationen können über Airflow Datasets präzise definiert werden. Beim Monitoring der Datenströme bis hinunter auf die verarbeiteten Datenpunkte selbst sind dedizierte ELT-Tools allerdings von Hause aus besser aufgestellt, hier lässt Airflow einigen Spielraum in der Ausgestaltung.
ELT-Prozess mit Apache Airflow - Unser Fazit
In unserem kurzen Überblick haben wir die Vorteile von ELT-Prozessen hervorgehoben und einige Vertreter der aktuellen Generation von ELT-Tools und deren Kombinationsmöglichkeiten mit Apache Airflow vorgestellt. Das Thema hat selbstverständlich noch viel mehr Facetten und eine unbegrenzte technologische Vielfalt. Letztendlich ist es wichtig, die richtige Wahl der Data-Warehouse-Architektur und -Tools zu treffen, um spezifische Herausforderungen zu lösen. Die Entscheidung für eine bestimmte Architektur, die eingesetzten Tools und die Entwicklungsprozesse sind immer spezifisch für jeden einzelnen Anwendungsfall und sollten genau geprüft werden. Während mit den technologischen Trends ständig neue Cloud-Plattformen auf den Markt kommen, kann schnell eine Richtung eingeschlagen werden, die an den tatsächlichen Bedürfnissen eines Unternehmens vorbeigeht.
Gerne besprechen wir mit Ihnen, welche Herausforderungen Sie bei der Datenverarbeitung und -analyse im Allgemeinen vorfinden und wie Sie ELT-Prozesse mit Apache Airflow in Ihrem Unternehmen gestalten und umsetzen können. Nehmen Sie einfach Kontakt zu uns auf - wir freuen uns auf den Austausch mit Ihnen!