






















Die digitale Transformation ist ein entscheidender Erfolgsfaktor für Unternehmen. Die Fähigkeit, wertvolle Erkenntnisse aus einer Fülle von generierten Daten abzuleiten, stellt einen signifikanten Wettbewerbsvorteil dar. Während heute immer mehr Daten für die statistische Analyse und Vorhersage geschäftskritischer Kennzahlen zur Verfügung stehen, steigt der Bedarf an Rechenressourcen für die zeitnahe Verarbeitung dieser Daten. Cloud-Dienste werben mit der nahtlosen und unbegrenzten Skalierung von Ressourcen und Kubernetes oder Apache Spark Cluster sind nur zwei Beispiele prominenter Technologien, die genau das ermöglichen.
Was aber, wenn Ihr Team Computing-Ressourcen in kleinerem Maßstab dynamisch skalieren muss? Wenn auf die zu verarbeitenden Daten nicht von verteilten Rechenclustern in der Cloud zugegriffen werden kann oder sie aus Compliance-Gründen vor Ort bleiben müssen? Einen High-End-Rechenclustern baut man nicht über Nacht in die Infrastruktur eines Unternehmens ein und der Betrieb rechnet sich möglicherweise auch gar nicht. Apache Airflow bietet sich als praktikable Zwischenlösung für Unternehmen, Data-Teams oder sogar einzelne Projekte an, da es von Haus aus die horizontale Skalierung von Berechnungsprozessen unterstützt.
Die Apache Airflow Celery Executor Architektur
Apache Airflow ist die führende Open-Source-Plattform für Workflow-Orchestrierung und Scheduling, welche die Programmiersprache Python, eine skalierbare Microservices-Architektur und das Configuration-as-Code Prinzip kombiniert. Jeder digitale Workflow kann mit dem Airflow-Framework implementiert und integriert werden. Hunderte von Unternehmen auf der ganzen Welt nutzen Airflow, um Daten- und Prozessflüsse wie ein Uhrwerk zu steuern. Heute betrachten wir eine Anwendungsmöglichkeit, die eigentlich ein Nebenprodukt der in die Apache Airflow Celery Executor Architektur eingebauten Skalierbarkeit ist: Airflow als verteiltes, horizontal skalierbares Rechencluster zu nutzen.
Airflow besteht im Wesentlichen aus einem Scheduling Service und einer Task Execution Engine. Der Scheduler interpretiert Workflow-Definitionen und reiht die einzelnen Aufgaben (Tasks) zur Verarbeitung in eine Aufgabenliste (Queue) ein, wenn alle Bedingungen erfüllt sind, also der festgelegte Zeitpunkt erreicht ist und alle vorgelagerten Aufgaben abgeschlossen sind. Die Execution Engine übernimmt die Verarbeitung der Tasks. Airflow kann mit mehreren Execution Engines für unterschiedliche Zwecke oder je nach den verfügbaren Infrastrukturkomponenten betrieben werden. Die am stärksten skalierbare Execution Engine basiert selbst auf Kubernetes und verursacht somit einen Teil der oben beschriebenen höheren Vorabinvestitionen. Die weniger aufwendige Alternative basiert auf dem Celery-Framework für verteilte Berechnungen, das einen gelungenen Kompromiss zwischen erforderlicher Infrastruktur und Skalierbarkeit bietet. Der Celery-Executor ist die Grundlage für den Anwendungsfall, den wir heute diskutieren.
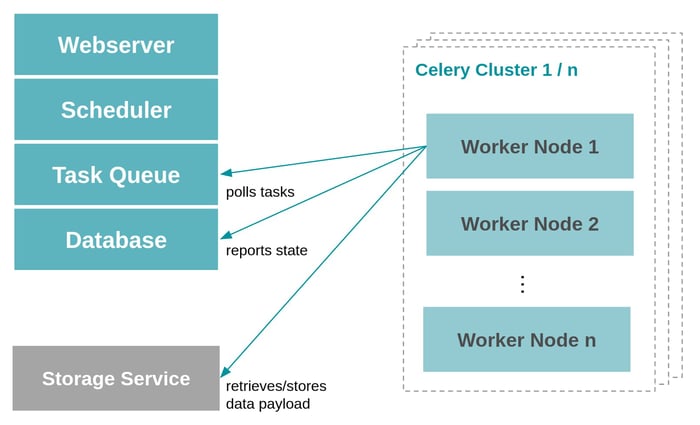
Vereinfachte Darstellung der Apache Airflow Architektur: dezentrale Worker-Noder stehen mit der Airflow Task Queue und der Systemdatenbank in Verbindung, um Aufgaben für die Verarbeitung abzurufen und Statusmeldungen zurückzuschreiben.
Die zu analysierenden Geschäftsdaten müssen über einen separaten Speicherdienst kommuniziert werden.
Celery selbst ist ein Python-Modul und kann unabhängig von Airflow ausgeführt werden, um Berechnungen horizontal zu skalieren, d.h. auf mehrere unabhängige Recheninstanzen (Worker) zu verteilen. Ein wichtiger Designaspekt von Celery ist, dass die Worker-Knoten zu jedem beliebigen Zeitpunkt einem Cluster beitreten können, ohne dass die zentrale Konfiguration aktualisiert werden muss. Jeder Worker kann eigenständig Aufgaben in der Warteschlange übernehmen und die Verarbeitung durchführen. Es müssen lediglich freie Rechenkapazitäten vorhanden sein und die Kommunikation mit Task Queue und Ergebnisdatenbank über das Netzwerk freigegeben sein. Ein Airflow-Celery-System kann diesen Aspekt nutzen, um seiner Task Execution Engine dynamisch zusätzliche Kapazitäten hinzuzufügen. Dies senkt zwar die Einstiegshürde für skalierbare Datenanalysen, automatisiert die Skalierung aber nicht so gut wie ein Kubernetes-Cluster. Für das jeweilige System und die Infrastruktur müssen einige Herausforderungen gelöst werden: Woher kommen die tatsächlichen Compute-Ressourcen und wie werden sie über die Notwendigkeit einer dynamischen Erweiterung der Verarbeitungskapazität informiert?
Optimieren Sie Ihr Workflowmanagement
mit Apache Airflow!

Airflow Prozessflüsse werden als directed acyclic graph (DAGs) bezeichnet und definieren eine Reihe von Aufgaben, deren Ausführungsreihenfolge sowie Metadaten, welche zwischen den Tasks übergeben werden. Da DAG-Definitionen vollständig in der Programmiersprache Python geschrieben werden, waren DAG-Entwickler mit ein wenig Aufwand schon immer in der Lage, Workflows zu erstellen, die Aufgaben zur Laufzeit dynamisch skalieren. Seit dem Release von Airflow Version 2.3 im letzten Jahr unterstützt das System die dynamische Task-Skalierung zur Laufzeit nativ. Für unseren Anwendungsfall der CPU-intensiven Datenanalyse können die Quelldaten dynamisch in kleinere Pakete oder Chunks aufgeteilt werden, die unabhängig voneinander von so vielen Kopien der Analyse-Tasks verarbeitet werden können, wie es Chunks gibt. Airflow bildet den Rahmen, um die Verarbeitung von Chunks auf Tasks aufzuteilen, die dann an die Airflow Task Execution Engine weitergegeben werden. Wenn wir nun der Task Execution Engine immer dann automatisch mehr Rechenkapazität zur Verfügung stellen können, wenn eine große Menge an CPU-intensiven Aufgaben zu verarbeiten ist, haben wir unser Ziel erreicht.
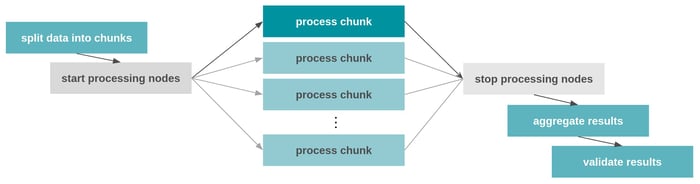
Schema eines Airflow DAG-Ablaufs, der einen Datensatz in kleinere Teilstücke aufteilt und diese in parallel ausführbaren Teilaufgaben verarbeitet.
Die grau dargestellten Prozessknoten deuten an, dass die verfügbaren Rechenressourcen des Systems vor und nach der CPU-intensiven Berechnung
hoch bzw. herunter skaliert werden können.
Skalierung der Rechenleistung mit Airflow: Praktische Herausforderungen
Die Verwendung von Airflow als verteilte Rechenmaschine war sicherlich nicht das primäre Ziel der Entwickler. Damit unser Anwendungsfall funktioniert, müssen einige der Werkseinstellungen des Systems angepasst werden. Zunächst einmal ist die Anzahl der Aufgaben, die Airflow gleichzeitig zur Ausführung vorsieht, standardmäßig begrenzt, um Überlastung zu vermeiden. Außerdem ist die Anzahl der gleichzeitig auszuführenden Tasks pro DAG begrenzt. Um eine deutlich höhere Skalierbarkeit zu ermöglichen, müssen die Airflow-Parameter parallelism und max_active_tasks_per_dag von ihren Standardwerten 32 bzw. 16 erhöht werden. Wie viele Aufgaben tatsächlich parallel abgearbeitet werden können, hängt wiederum von der Anzahl der Worker und deren Prozessorkapazität ab.
Wenn Sie Airflow mit den Docker-Compose-Vorlagen aus der offiziellen Dokumentation einrichten, steht dem System ein einziger Worker zur Verfügung. Über die Container-Replikationsmechanik von Docker Compose kann diese Anzahl jederzeit erhöht werden. Natürlich ist die einfache Erweiterung der Anzahl der Worker auf einem einzelnen Docker-Host-Server immer noch durch die auf diesem Server verfügbaren Ressourcen begrenzt. Eine echte horizontale Skalierung erfolgt durch die Verteilung von Worker-Nodes auf mehrere Hosts, um dem Basissystem mehr Ressourcen hinzuzufügen. Damit entfernte Arbeitsknoten die Verarbeitungsprotolle mit Airflow kommunizieren können, müssen sie so konfiguriert werden, dass sie die Protokolle über einen integrierten Webservice austauschen, der für den Airflow-Hauptserver zugänglich sein muss. Zu guter Letzt müssen die DAG-Definitionsdateien und Python-Module zwischen allen Airflow-Komponenten synchron gehalten werden. Diese können in eigens gebaute Airflow-Docker-Images integriert werden oder es können mittels automatischer Hilfsfunktionen ständig die neuesten Dateiversionen aus einem Git-Repository synchronisiert werden. Unserer Erfahrung nach hängt es stark von der vorhandenen Infrastruktur und dem Systemkontext ab, wie man alle diese Stellschrauben optimiert.
Sobald Sie herausgefunden haben, wie Sie Worker dynamisch in die Airflow-Umgebung integrieren, bleibt noch die Anzahl der parallelen Threads zu konfigurieren, die jeder Celery Worker verarbeitet. Airflow fasst diese Einstellungen in den Parametern worker_concurrency und worker_autoscale zusammen. Letzterer ermöglicht es jedem Worker, dynamisch zusätzliche CPU-Threads zu starten, wenn die Aufgabenwarteschlange voll ist, und überschreibt damit effektiv den erstgenannten, statischen Parameter.
Bei der Konfiguration der verschiedenen Skalierungsmechanismen ist zu bedenken, dass die Anzahl der tatsächlich verfügbaren CPU-Kerne eine Grenze für die Anzahl der parallel verarbeitbaren Aufgaben darstellt. Wenn die Zahl der parallelen Aufgaben die Zahl der CPU-Kerne übersteigt, führt dies zu einem Overhead an Kontextwechseln in den unteren Schichten des Betriebssystems und der Hardware und wird zu Reibungsverlusten führen.
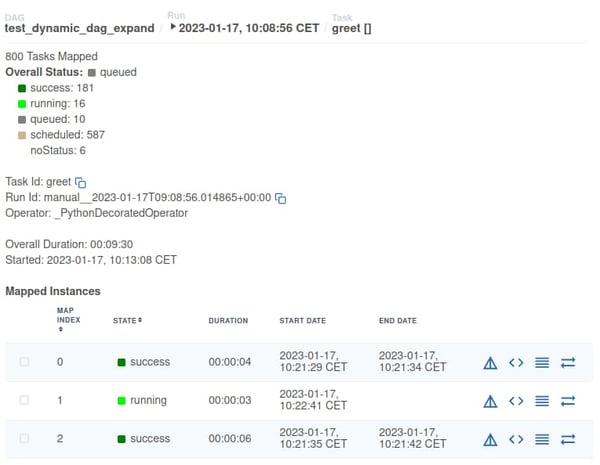
Screenshot der Benutzeroberfläche von Apache Airflow (Version 2.5): Es werden Informationen über einen Airflow Task angezeigt, der dynamisch auf 800 Instanzen erweitert wurde. Von den 800 Unteraufgaben sind 16 als aktiv gekennzeichnet und werden vom System parallel verarbeitet.
Randbedingungen und weitere Möglichkeiten
Das hier diskutierte Anwendungsszenario ist insofern recht spezifisch, als es von einer Reihe von Randbedingungen ausgeht: dass dem Team keine hoch-skalierbare Infrastruktur wie Kubernetes, Databricks oder Apache Spark zur Verfügung steht; dass die Ausführung von Airflow mit oder ohne Docker eine Option ist; dass die Skalierung von Rechenressourcen oder genauer gesagt von virtuellen Servern möglich ist, vielleicht sogar über eine API automatisiert werden kann. Zu guter Letzt muss die durchzuführende Datenanalyse eine Form haben, dass sie mittels einer klassischen Divide-and-Conquer-Herangehensweise zerlegt, Teilstücke unabhängig voneinander verarbeitet und die Ergebnisse aggregiert werden können.
Aus Projekterfahrungen und Gesprächen mit unseren Kunden wissen wir, dass solche oder vergleichbare Einschränkungen recht häufig vorkommen und kreative Lösungen erfordern, die in kurzer Zeit umgesetzt werden können. Der Einsatz des Apache Airflow Celery Executor, wie wir ihn hier beschrieben haben, kann eine solche kurz- bis mittelfristige Lösung sein. Auf diese Weise können fachliche Ergebnisse erzielt werden, bevor ein strategisches Infrastruktur- oder Cloud-Migrationsprojekt gestartet werden kann.
Wir haben mit unseren Ausführungen hier nur einen Teil der Möglichkeiten beschrieben, wie die Apache Airflow Celery Executor Engine für parallele Berechnungen genutzt werden kann. Es sind auch fortgeschrittenere Szenarien denkbar: Die Integration der API-gesteuerten Skalierung oder des Starts von Rechenressourcen als Teil des DAG-Flows selbst oder die Verwaltung mehrerer Rechencluster durch die Nutzung verschiedener Celery-Worker-Queues. Für all diese Möglichkeiten gilt der übliche Hinweis, dass die Komplexität zwar aus der Verantwortung einzelner Entwickler oder Teams in das System selbst verlagert werden kann, sie aber nicht auf magische Weise verschwindet. Für den Test, Betrieb und die Optimierung solch komplexer Systeme sind tiefgreifende Kenntnisse in den Bereichen Airflow, Celery, Microservices, verteilte Systeme und Computernetzwerke erforderlich.
Ist Ihre Organisation oder Ihr Team mit ähnlichen Herausforderungen konfrontiert oder brauchen Sie jemanden, mit dem Sie architektonische Entscheidungen bezüglich skalierbarer Compute-Frameworks diskutieren können? Vereinbaren Sie gerne ein erstes Gespräch mit unserem NextLytics Data Science and Engineering Team. Wir sind gespannt auf Ihre Anwendungsfälle und entwickeln mit Ihnen Lösungen, die für Ihre spezifischen Anforderungen und Systemkontext optimiert sind.


