






















Apache Airflow promotes itself as a community-based platform for programmatic workflow management and orchestration. For data teams in charge of ETL pipelines or machine learning workflows, these are key functionality and a code-based system might just play to the strengths of your tech-savvy team members. Your own instance of Airflow is quickly set up following along with the project’s official documentation but immediately raises as many questions as it solves! Some challenges you face after the initial exploration may be:
- deciding upon deployment processes for development, testing, and production stage system environments
- defining a robust workflow development framework across these stages
- finding the right amount of rules and conventions to make it all integrate seamlessly in your specific use case
Apache Airflow is a powerful tool with many benefits but needs careful tailoring to perfectly integrate into any given process chain. We give you an overview of some common challenges, approaches to solve them and a hands-on example deployment in today’s best practices collection!
Challenges
To understand some of the challenges that Airflow presents for the operating team, let’s recap a few facts about how Airflow works: As the above definition clearly states, Airflow is a platform aimed at people that know how to program. There is no user interface to create workflows (or “directed acyclic graphs”, DAGs, as they are called). If you want Airflow to do more than run one of the example DAGs, you have to write Python code. Once the Python code defining your first DAG is completed, you have to put that file in the correct directory of your Airflow system so that it will be recognized. Again, no user interface to upload your new DAG.
One fundamental convention of DAG development states that you should not put custom code into the DAG definition file. If you want to execute some custom code (i.e. when not all your processing needs are met by the existing Operators or Sensors), you have to put that code somewhere else in the Python environment that operates Airflow to run it your DAG.
All this is quickly figured out and done on a single computer where you run all Airflow components as Docker containers using compose files, for which plenty of examples are available on the internet. Once these processes need to run in a multiple stage dev/test/production environment operated by one or even multiple teams, it gets complicated:
How do DAG developers interact with Airflow? How are DAGs tested? How and when should DAGs and Plugins be deployed? Who is responsible for which aspect of the deployment pipeline?
There is no single correct method to address these questions but many different approaches, a few of which we will discuss.
CI/CD and the Dilemma of Choices
The popular terms continuous integration and continuous delivery (CI/CD) summarize methods and strategies to improve software development quality by automatically testing and running code in the target environment. CI/CD frameworks enable all kinds of automated process steps based on changes that happen on the source code base. Since Airflow and all its components are defined in source code, it is a fitting approach to create a robust development and deployment framework with CI/CD tools.
 Again, there is no single correct method of how to actually implement this. You have the dilemma of choices regarding different CI/CD frameworks as well as pipeline design choices specifically regarding Airflow, and even the way your teams work and collaborate in their routines. For our example below, we chose to work with Gitlab CI/CD as the framework. The same results can be achieved using any given alternative on the market, whether your infrastructure is cloud-based and you apply built-in CI/CD tools or connect to a third-party service like Travis CI; or you have access to an on-premises instance of open source frameworks like Jenkins, Drone, or Woodpecker CI. Instead of going into details in this regard, we will focus on the options you have regarding Airflow.
Again, there is no single correct method of how to actually implement this. You have the dilemma of choices regarding different CI/CD frameworks as well as pipeline design choices specifically regarding Airflow, and even the way your teams work and collaborate in their routines. For our example below, we chose to work with Gitlab CI/CD as the framework. The same results can be achieved using any given alternative on the market, whether your infrastructure is cloud-based and you apply built-in CI/CD tools or connect to a third-party service like Travis CI; or you have access to an on-premises instance of open source frameworks like Jenkins, Drone, or Woodpecker CI. Instead of going into details in this regard, we will focus on the options you have regarding Airflow.
|
Code Repository |
CI/CD Engine |
Deployment |
|
GitLab Azure Repos GitHub AWS CodeCommit Bitbucket Gitea … |
GitLab CI/CD Azure Pipelines AWS CodePipeline Bitbucket Pipelines Travis CI Jenkins Drone Woodpecker CI … |
Docker Kubernetes Python/PyPI … |
Alternatives exist for each of the components necessary to create an end-to-end DAG deployment pipeline.
Initially, you should consider whether you want to couple the deployment of your Airflow platform tightly or loosely with the Airflow DAG development process. Tight coupling can be achieved by building a custom Airflow Docker image that contains all your custom DAGs (and their dependencies) so your entire system has to be re-deployed when changes happen on any DAG. Loose coupling can be achieved by enforcing strict separation of the Airflow platform and DAG development. Changed DAG code would be delivered into the running base system without triggering a full re-deployment. Which route to choose depends on a couple of factors specific to your setting, for example the number of DAGs you want to run, the number of teams or people that will develop DAGs, the complexity of the DAGs themselves and how many custom Python module dependencies they bring.
In general, loose coupling scales better with the number of DAGs, developers, or when responsibilities for workflows are shared across multiple teams. Tight coupling can reduce the complexity of your overall framework as tasks are centralized in one place. Switching from one to the other can be done if circumstances change, e.g. if the system grows over time, but comes at the usual cost of changing an already established routine. Neither approach fully decouples the operation of the platform from the development of DAGs but the choice influences how you have to lay out the actual CI/CD pipeline and potential cross-pipeline interactions.
|
Deployment approach |
tight coupling |
loose coupling |
|
Pros |
|
|
|
Cons |
|
|
Comparison of advantages and disadvantages between tightly and loosely coupled deployment methods of Airflow and DAGs. The more loosely coupled the approach, the more independent DAG development is from Airflow system operations.
Let’s assume a loose coupled deployment and focus on the DAG development workflow. DAG development CI/CD pipelines should provide developers with an easy way to create new DAGs, have them automatically tested in isolation (unit tests) and in context (integration tests), possibly reviewed by at least a second developer, and deployed into the target environment. Following that, the Airflow platform takes over orchestration duty and starts the tasks as scheduled. A well-defined CI/CD pipeline can reduce the actual developers’ responsibility to just providing new DAG source code (and test definitions) at the right place, i.e. the correct Git repository.
Optimize your workflow management
with Apache Airflow!

How you lay out your CI/CD pipeline depends on how the Airflow system(s) are deployed and how code-based artifacts need to be distributed into the system. This might mean delivering the DAG files into the correct directory in the host server’s file system or uploading the files into an object store service, for example AWS S3 if you run a cloud-based Airflow service managed by Amazon.
To put the lid back on this Pandora's box of choices, let’s go into a practical example based on how we set up an internal development environment at NextLytics.
Practical example: GitLab CI/CD
In this example, we use GitLab as the source code versioning system and the integrated GitLab CI/CD framework to automate testing and deployment. We go with a loose coupling approach and split the deployment and operations of the base Airflow system from the DAG development process. The Airflow system is run on a remote host server using that server’s Docker engine. Python modules, Airflow DAGs, Operators, and Plugins are distributed into the running system by placing/updating the files in specific file system directories on the remote host which are mounted into the Docker containers. The Airflow “lazy loading” option has been disabled to make the system check for changed/updated modules regularly.
All DAGs for the Airflow instance will be developed in a single Git repository (a project in GitLab). A review of source code is enforced by GitLab settings: changes can only be merged into the main branch via a Merge Request which in turn requires review by a second pair of eyes before it can be completed as well as all that test stages of the CI pipeline pass successfully.
.png?width=850&name=02_gitlab-project-architecture%20(1).png) Side-by-side comparison of tightly and loosely coupled architectures regard the separation of logical components into GitLab projects. The loosely coupled architecture on the right is used in our practical example.
Side-by-side comparison of tightly and loosely coupled architectures regard the separation of logical components into GitLab projects. The loosely coupled architecture on the right is used in our practical example.
The source code is split into subdirectories for DAGs, Airflow Operators, and custom Python modules. Contents of these will be copied into the respective directories mounted into the Airflow runtime during the deployment stage of the CI/CD pipeline.
To test newly developed DAGs, three stages have to be passed:
- Python syntax is correct and all unit tests succeed
- DAG is imported without errors in Airflow (see code example below)
- DAG is run without errors in Airflow
The first of these stages is self-contained in that it only depends on the changed code and associated tests implemented by the developer. The second and third stages require an Airflow system for test execution. We provide this environment on-the-fly during pipeline execution: A throw-away Airflow system will be created, used for the two tests, and completely disposed of again afterwards using Docker commands specified in the CI/CD manifest.
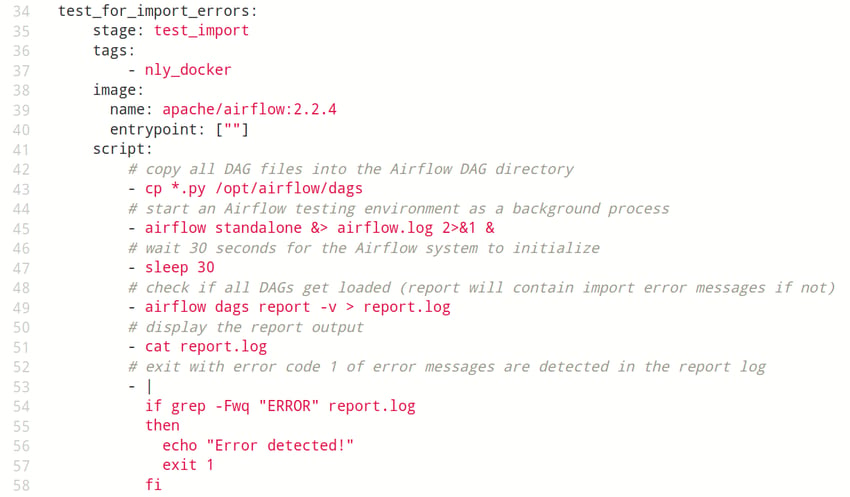 Example code: A GitLab CI/CD job definition that loads a set of Python files containing DAG definitions into a throw-away Airflow engine
Example code: A GitLab CI/CD job definition that loads a set of Python files containing DAG definitions into a throw-away Airflow engine
and checks for import errors.
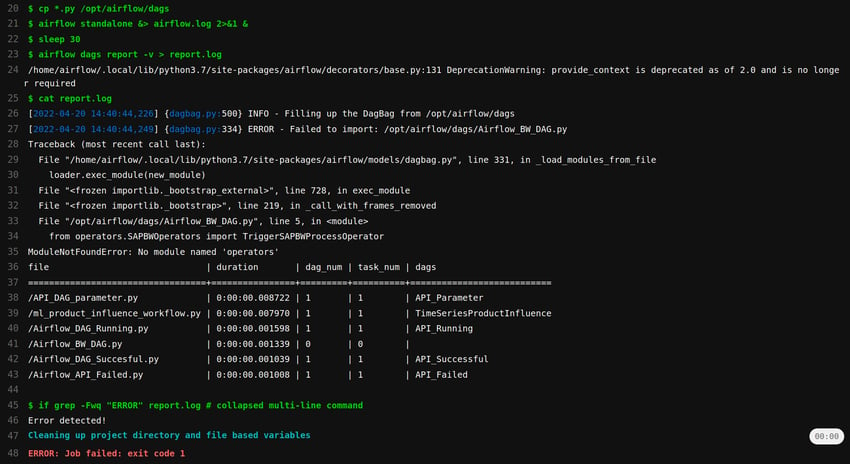 Example log output: Results of running above GitLab CI/CD job to test DAGs for import errors. In this case, an import error happens (due to a custom Operator missing from the Airflow environment) and the job fails, preventing the CI/CD pipeline from executing the following stages.
Example log output: Results of running above GitLab CI/CD job to test DAGs for import errors. In this case, an import error happens (due to a custom Operator missing from the Airflow environment) and the job fails, preventing the CI/CD pipeline from executing the following stages.
Details of implementing the deployment phase of the pipeline are again up to configuration due to multiple options offered by GitLab CI/CD: Remote code execution on the host server could be enabled by setting up a dedicated “GitLab Runner” service or by remote login using the SSH protocol. Delivery of the changed files can be achieved by explicitly pushing into the remote file system or by checking out the entire Git repository on the remote host. Choices may vary based on many factors including conventions, routines, or simply preference of the people involved. Our example uses the SSH-based remote login as well as SCP-based delivery of files as these reduced assumptions about the required state of our host system.
The described example shows one way of handling DAG development, testing, and deployment using GitLab CI/CD automation. Implementing meaningful tests is still largely up to developers and creating the necessary one-time environment for complete integration testing requires some deeper knowledge of both the CI/CD framework and third-party services the DAGs have to interact with.
GitLab CI/CD - Our Conclusion
Many variable building blocks are necessary to create a well-defined, robust, and use-case-specific operations framework for Apache Airflow and DAG development. The abundance of choices and alternatives for available tools and implementation details require deep understanding of the ecosystem and the scenario’s specific requirements. Our example showcases one possible approach using GitLab CI/CD as the framework. In production use, teams’ conventions and shared responsibilities among stakeholders can be more important factors for shaping the CI/CD process than technological constraints. If you would like to set up a well-fitting Airflow operations framework or want to get some expert feedback on your current implementation, get in touch with us today!

