/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























In last week’s NextLytics blog article, we highlighted the common capabilities of feature store software and discussed the reasons to contemplate the investment into such an additional component.
This week, we focus on the options your organization has if you want to implement a feature store and which arguments should be considered.
Recap
Let’s begin with a short reprise of what a feature store is and how your organization or team might benefit from introducing one into your machine learning architecture.
The Feature Store Concept
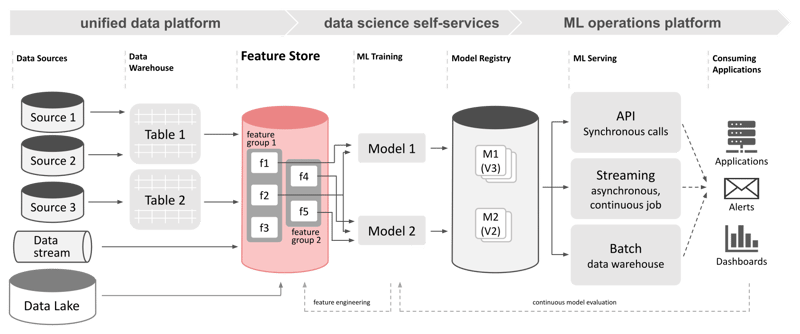
The concept of dedicated feature stores has been around for a few years now. Large tech and internet companies have coined the term to describe their emergent solutions to a remaining blank spot on the data landscape right in the middle of the data processing chain. As of today, feature stores are reportedly an integral part of the infrastructure of successful data-driven companies and a cornerstone of scalable machine learning frameworks. Feature stores act as an interface between different data sources and machine learning development and operations frameworks. They can contribute to a more efficient feature engineering and data discovery process and free data scientists from repetitive tasks.
 Do you need a Feature Store?
Do you need a Feature Store?
Are your data scientists spending more time on data wrangling and feature engineering than actually developing and optimizing machine learning models? Are the same features prepared again and again for every AI application you operate? Do historical copies of feature data sets and training data sets pile up in a data lake? Are your data engineers launching more and more RESTful APIs to serve custom metrics to machine learning applications? Or does the number of custom tables created in an analytics database by your ML team grow exponentially?
If you can answer one or more of these questions with a definitive “yes”, you might want to investigate the possibility of introducing a dedicated feature store into your data science infrastructure.
Implementation Options
But what options are available for your organization if you decide to incorporate a feature store into your current data science architecture?
Three approaches can be surveyed in blog articles, whitepapers, and conference talks:
- use an integrated solution by your machine learning framework vendor
- adapt open source software to your custom infrastructure
- build an in-house solution to solve specific needs
Integrated Product
Relying on the existing product by your established vendor is definitively the most convenient option. AWS, Databricks, and Microsoft Azure incorporate feature store components in their general “AI” frameworks that come equipped fully integrated with user interfaces and user management services. The same goes for most vendors that offer on-premise turnkey solutions based on proprietary software.
Integrated feature stores boast little to no effort when first added to your machine learning architecture. Apart from some initial configuration, these solutions are ready for immediate usage and most work may be spent defining the workflow conventions among the users, probably your organization’s data engineering and data science teams. These quick wins may come at the expense of working around the product’s specific functionality or API that is predefined and not necessarily a perfect fit for your current workflows and processes. Uptake of new functionality into these vendor-managed products may be slower or harder to influence for a single customer in comparison to open source projects.
Furthermore, these feature store solutions are off-limits, if your organization is not already using the respective product or not able or willing to migrate.
Open Source Software
Adopting an open source solution allows your organization to hand-pick the best suited solution, possibly testing multiple alternatives before deciding on the optimal fit. Dedicated open source solutions for feature stores are still few and far between, though.
Feast (Feature Store) has been the first open source solution in the market and is still growing. At first glance, Feast comes across as an easy to use system well integrated with the Python data science stack and supporting a diverse set of third-party service connections. With Azure building their feature store solution based on this project and willing to contribute to the code base, Feast looks very promising.
An alternative solution is the Hopsworks feature store which comes integrated into a larger full-service machine learning operations framework.- Built on top of proven big data technologies like Apache Spark and Apache Hudi, the Hopsworks solution is ready to scale to the maximum. The scalability comes at the cost of complexity from an operational perspective which makes it hard to spin up a local instance for a test ride if you don’t have access to at least a small Kubernetes cluster. The overall software is well accessible both from an API and user interface perspective; good visualizations and navigation of the feature store in an intuitive web-based interface are a definitive advantage compared to Feast.
Download the Whitepaper and discover the potential of Artificial Intelligence and Machine Learning!

In-house Development
If neither fully integrated product or open source solution meet your specific requirements, building a custom in-house solution may be a viable alternative.
The majority of data-driven companies that have publicly discussed their feature store solutions have chosen to implement an in-house solution. Building yourself is a sizable investment in the beginning as you either need the qualified software engineers on your staff or find the right development partner. Fitting the resulting system exactly to established system context, processes, and strategy may result in significantly higher user satisfaction as well as lower effort in change management and maintenance costs.
We have already implemented machine learning architecture solutions for our customers that re-used existing systems as a feature store. In these projects, we achieved exactly the functionality required by the data science team with little custom software development. In other use cases, implementing a lean RESTful API as a harmonization layer may serve all of a teams’ needs with regard to optimizing the feature engineering stage.
Example: Integrating Feature Store and Apache Airflow
The following Python code snippet exemplifies how relatively easy interaction with a feature store is, in this case using the Hopsworks feature store and respective Python library “hsfs”. First, we create a feature group based on a Pandas DataFrame object:
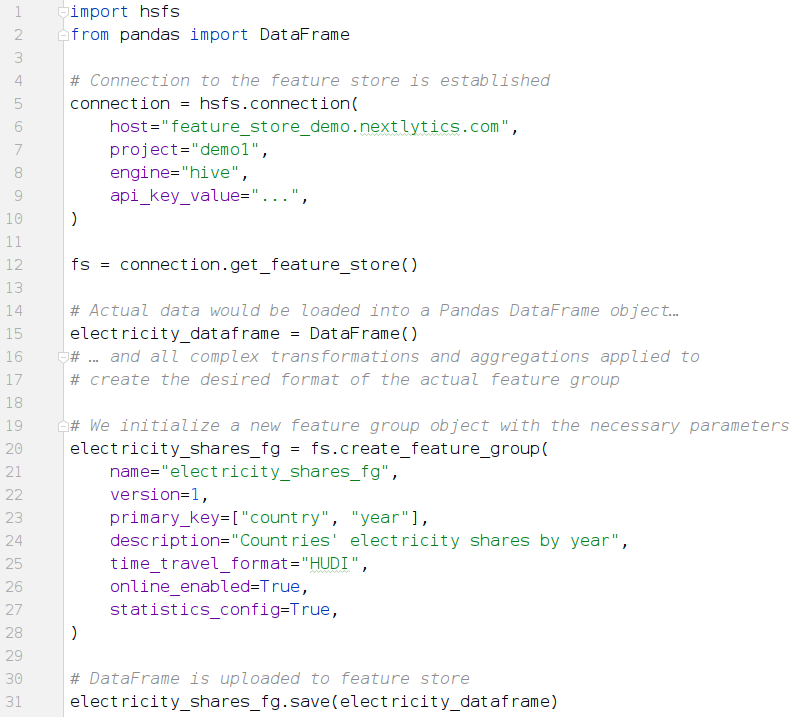 Python Code Example 1: How to create a new feature group based on a Pandas DataFrame
Python Code Example 1: How to create a new feature group based on a Pandas DataFrame
and upload it to the Hopsworks feature store.
The example code for creating and registering features would be isolated into a dedicated feature engineering stage of our overall workflow. Retrieving the data from the feature store in the actual machine learning development boils down to three simple statements in the code, as shown in the second code snippet:
- Connecting to the store (lines 1-12)
- Creating pointer variables (15-16)
- Retrieving the actual data that is already formatted correctly for downstream processing (19-24)
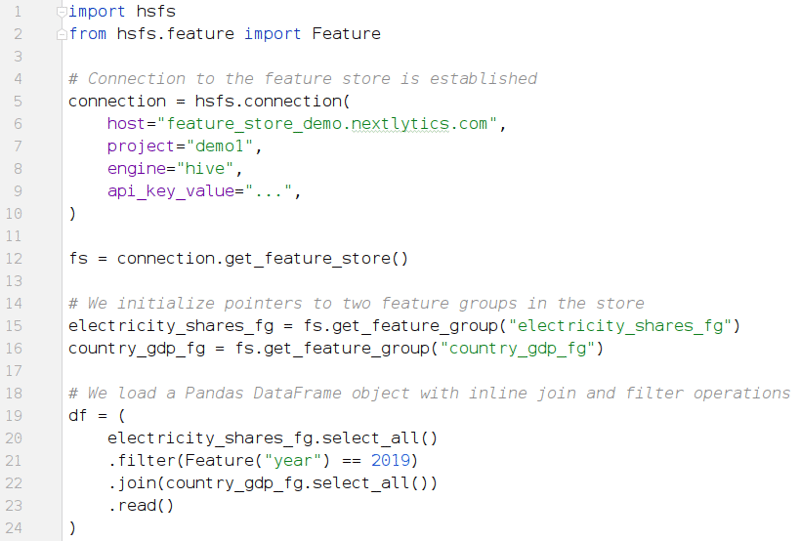
Python Code Example 2: How to join, filter, and retrieve data from a Hopsworks feature store.
In the full processing chain, creating, registering, uploading, and updating features would be extracted from the actual code that trains or applies a machine learning model. These extracted steps form a new layer of feature ingestion jobs. Feature engineering and ingestion can be managed by any capable ETL orchestration tool like for example by an instance of Apache Airflow as central ML workflow controller.
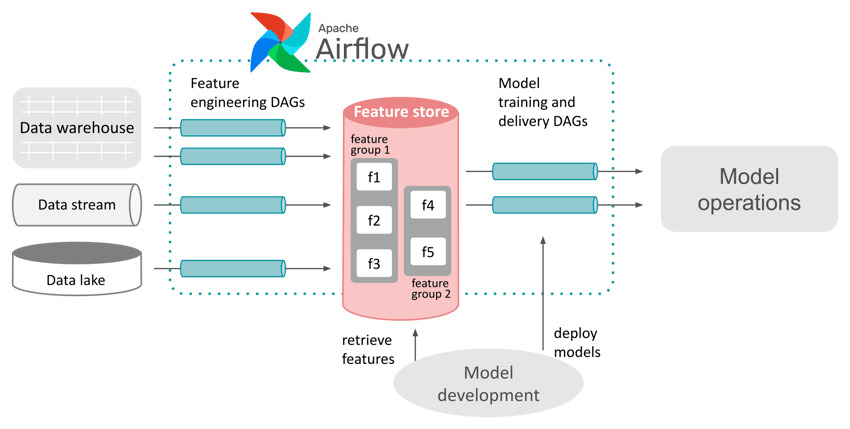
Using Apache Airflow to orchestrate a dedicated feature engineering stage in the
machine learning development and operations workflow.
This example shows how a feature store can be integrated into an existing machine learning operations framework. This blueprint works with a specialized open source feature store software as well as with any in-house feature store implementation. It demonstrates how the benefits of a feature store component and dedicated feature engineering stage in the processing pipeline may be accessible for your organization regardless of what your current architecture looks like.
Conclusion
The feature store is one of the most promising trends in the data engineering and machine learning community. Platform service providers have recognized the potential and added integrated feature stores to their machine learning infrastructure portfolios. Open source software alternatives are available both for autonomous adoption by your infrastructure team and as managed services.
The dedicated feature store implementations are still in the maturation process, though. To gain the most out of the feature store concept, a custom in-house solution may be a viable and quick win solution for your organization.
The success of introducing a feature store depends to a large part on precise analysis, requirements engineering, and a realistic evaluation of the risks and rewards of implementation choices. An experienced partner like NextLytics can provide valuable insights in the assessment of alternative solutions and guide you to the best decision for your organization.
Do you have further questions about feature stores as an addition to your data science infrastructure or do you need an implementation partner?
We are happy to support you from problem analysis to technical implementation. Get in touch with us today!

