






















In the previous article you have learned about the advantages of SQLScript. While SQLScript transformation routines are undoubtedly beneficial then it comes to performance, there are also some limitations. These are discussed in this article.
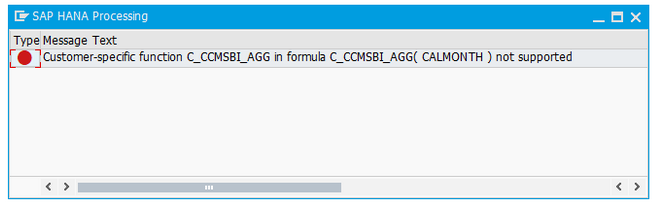
Transformations are not always executed in the SAP HANA database. Within the transformation you can check if the HANA runtime is supported. Use the check button in the Runtime Status area.
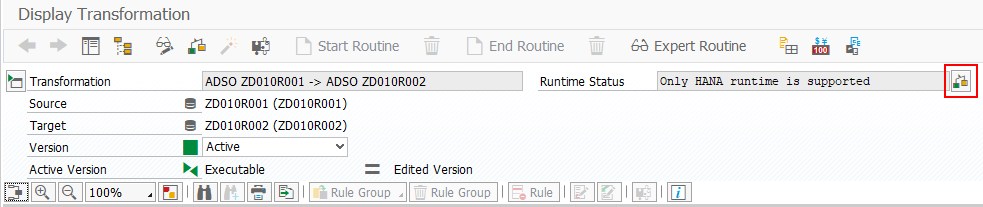
If the transformation cannot be performed at the HANA database level, the list of unsupported functions is displayed.
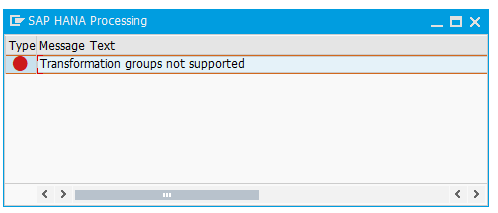
In the following I explain the 10 most important restrictions.
1. Supported InfoProviders
Please note that not all InfoProviders can be used as the target of a HANA transformation. The following objects are supported as targets:
- DSO: Standard and write-optimized types
- ADSO: all types, except the "InfoCube" setting
- Semantically partitioned objects based on DataStore objects
- Open hub targets with database tables (without database connection) or third-party tools
As of SAP BW 7.5, the following objects can also be used as targets:
- ADSO: all types, including „InfoCube“ setting
- InfoObjects
- InfoCubes
However, only the extraction and transformation are performed with SAP HANA. The SIDs are generated in ABAP. Therefore, the use of AMDP Script in a simple transformation with 1:1 assignment does not lead to any performance improvement. We therefore recommend to use ADSOs with the Enterprise Data Warehouse Architecture templates when modeling.
2. Queries as InfoProviders cannot be used as sources
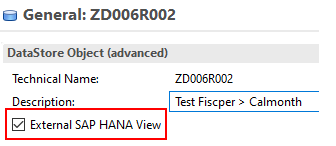
In addition, queries that have been defined as InfoProviders cannot be used as source of a HANA transformation. You can circumvent this restriction by defining an external SAP HANA View based on the query.
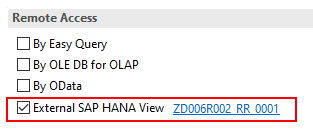
The setting “External SAP HANA View” must also be set for the InfoProvider.
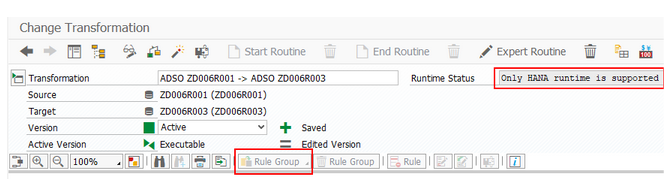
3. Transformation with rule groups is not possible
Furthermore, it is not possible to perform transformations with rule groups in HANA. Once a rule group is created, only execution in the ABAP environment is possible.
4. Nearline connections are not supported
Nearline Storage provides the possibility to outsource data via a data archiving process. In doing so, the data volume of InfoProviders is reduced, while the data is still available for queries. Unfortunately, these nearline connections cannot be used within HANA transformations.
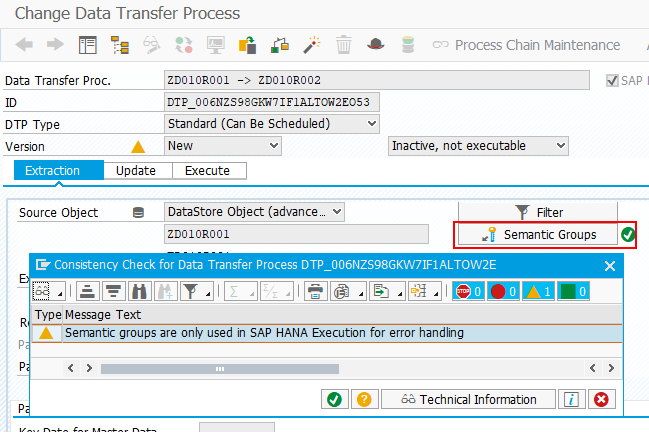
5. Semantic groups in DTPs
Please also note that the DTP setting Semantic Groups has no influence on the sequence of the extracted data. This setting only affects the grouping of the data sent to the error stack.
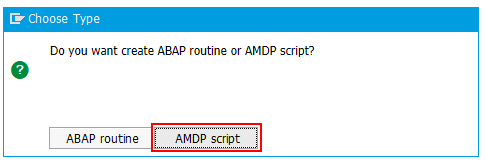
6. ABAP routines not possible within the transformation
If you create a routine within a transformation, you have to choose either ABAP or SQLScript. Both together are not possible.
ABAP start, end or field routines cannot be combined with SQLscript routines.
If you use several transformation routines that are connected by an InfoSource, the following rule applies. Once a preceding transformation is implemented in ABAP, the second transformation cannot be implemented in HANA. However, if the first transformation is executed in HANA, the second transformation can be executed in ABAP. As a reminder, remember the following principle - once the data is in the ABAP stack, pushdown is no longer possible.
Increase the performance of your BW with SQLScript

7. Custom functions in the Formula Editor
If you create routines using the formula editor, you may only use the functions delivered by SAP. Custom functions are not supported.
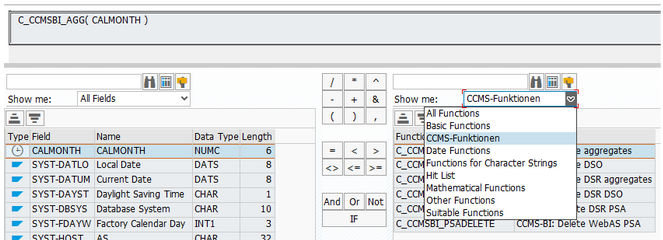
When checking the HANA support in the runtime status area of the transformation a corresponding message is displayed.
8. Data verification
Data transformed with an AMDP script is written directly to the data target. The system does not perform any data validation. The output of the transformation must be in tabular form, using a predefined order of columns and the values must correspond to the specified data types.
Please note that the output data must not only correspond to the data type used in SAP HANA, but also to the BW-specific definition for each field. For example, the data type DATE with the YYYY-MM-DD format valid in HANA is not compatible with the data type DATS in the YYYYMMDD format.
In addition, watch out for the following pitfalls:
- NULL values are not allowed under any circumstances and will lead to an error. In this article you will learn how to protect yourself against this inconvenience
- Initial values for InfoObjects depend on the respective data type. For example, initial NUMC fields may only be filled with zeros, although all characters are allowed for the database field
- Permitted characters for InfoObjects of type CHAR are defined in BW Customizing (transaction RSKC)
- Lower case letters are only allowed if the corresponding setting is activated for the InfoObject
- Fields must be filled in the internal BW format, especially if there are conversion exits. For example, fiscal periods are stored in YYYYMMM format, but displayed externally as MMM/YYYYY for the user
- Also note that values are not compared with BW master data tables. This could result in unwanted entries
- If a constant is assigned to an InfoObject, the exact (internal) value must be specified for the corresponding field
9. Error handling in SAP HANA
Error handling is important in this context. As of SAP BW 7.5 SP 4, error handling can be activated in the DTP. This changes the signature of the ABAP-managed database procedure and enables error messages to be returned to SAP BW.
However, error handling with BW on HANA and BW/4HANA 1.0 is not supported for the HANA runtime. So, the incorrect data records are written to the error stack, but cannot be emptied via an error DTP.
With BW/4HANA 2.0 the error handling for the HANA runtime has been fundamentally revised, so that you can also use the error DTP. However, you should consider the performance aspects before using the error handling in the productive environment.
For more information, see SAP Note 2580109 - "Error handling in BW transformations and data transfer processes in SAP HANA runtime".
10. Handling of packages with very large data volumes
If you work with very large amounts of data (e.g. hundreds of millions of data records) in BW, you must note that extraction with the HANA execution only takes place with the following InfoProviders:
- DataStore-Object (advanced)
- DataStore-Object (classic)
- SAP HANA DataSource
InfoCubes, however, are not supported. If you use an InfoCube as a source, data is not extracted in packages. This can exhaust the memory capacity and lead to out of memory errors.
For more information, see SAP Note 2329819 - “SAP HANA execution in DTPs (Data Transfer Processes) - Optimizations”. Possible solutions are offered in SAP Note 2230080 - “Consulting: DTP: Out of memory situation during 'SAP HANA Execution' and the 'Request by Request' Extraction”.
Our Summary - HANA SQLScript
If you consider restrictions and criteria for switching to SQLScript, as mentioned in this article, you can benefit from enormous performance advantages. In our consulting practice we have observed cases with more than 15 times better performance. The customer can now focus on data analysis and achieving results instead of waiting for the data to be processed.
Therefore, you should always use SQLScript for data-intensive logics to avoid additional data transfers between application and database servers.
Contact us, we will help you to choose the right strategy and individual implementation.

