






















In the previous article, Two options for error handling with SAP BW and SQLScript, we presented the different scenarios of error handling within SAP BW on HANA and BW/4HANA. In this article, we will take a closer look at the first scenario.
In this scenario, the mechanisms of the DTP error handler are used. The incorrect records are written to the error stack, where they can be corrected manually afterwards. In the SQLScript transformation, the erroneous records are written to the errorTab table. In order to work with this feature on a BW/4HANA system, you need to activate the setting Allow Error Handling for HANA Routines in the transformation.
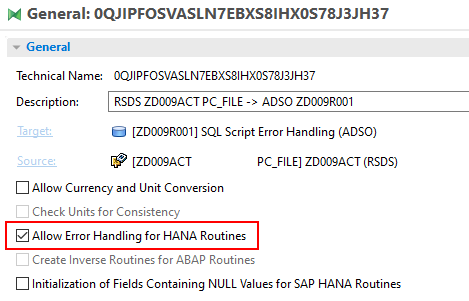
The errorTab table consists of two fields: ERROR_TEXT and SQL__PROCEDURE__SOURCE__RECORD. In the ERROR_TEXT field you can output the description of the error. The SQL__PROCEDURE__SOURCE__RECORD field serves as an identifier for the respective record.
To illustrate how the error stack works, we use an AMDP routine that takes over all fields unchanged. At the same time, the COMP_CODE column is checked for invalid characters and the incorrect records are written to the errorTab table. To do so, we use the LIKE_REGEXPR command, which recognizes search patterns based on Perl Compatible Regular Expression (PCRE). We use the pattern [lower] to check if the field contains lowercase letters. We also use the LIKE command to find all records that begin with an exclamation mark. Finally, we also define all company codes as incorrect if they have the value # (not assigned).
outTab =
SELECT comp_code, currency, '' as recordmode, amount, record, SQL__PROCEDURE__SOURCE__RECORD
FROM :inTab;
errorTab= SELECT 'Check field value!' AS ERROR_TEXT,
SQL__PROCEDURE__SOURCE__RECORD
FROM :intab
WHERE comp_code LIKE_REGEXPR '.*[[lower]].*'
OR comp_code LIKE '!%'
OR comp_code = '#';The data source contains two incorrect records - the company codes (0COMP_CODE) !200 and #.
|
0COMP_CODE |
0AMOUNT |
0CURRENCY |
|
1000 |
100,00 |
EUR |
|
!200 |
200,00 |
EUR |
|
# |
300,00 |
EUR |
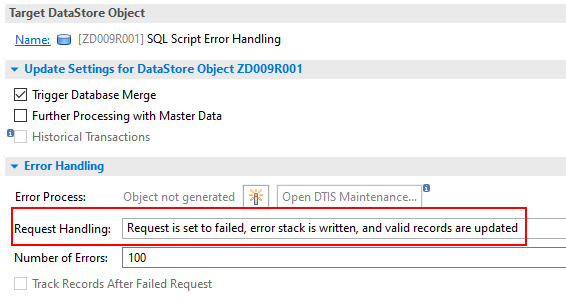
Furthermore, we make the following settings in the DTP. First, error handling must be switched on. To do this, switch to the Update tab and select the option Request is set to failed, error stack is written, and valid records are updated under Error handling.
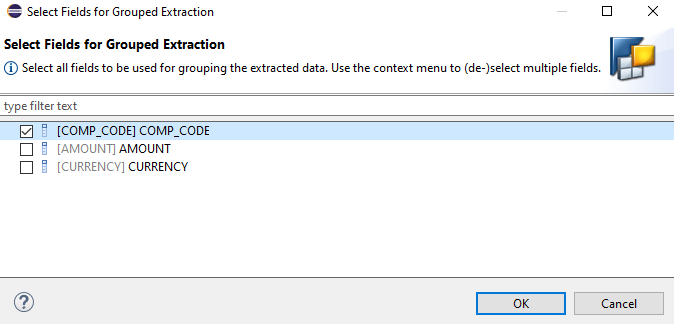
For the error handling on the HANA database we also need to define semantic groups in the Extraction tab. These are used to determine incorrect records. For example, in case of a purchase order and purchase order item, we can define the purchase order as the key. If one item is incorrect, the entire purchase order will be marked as incorrect.
In our example it is quite simple - the company code 0COMP_CODE serves as key. Therefore, please select COMP_CODE under the Extraction Grouped By option.
|
Notice: |
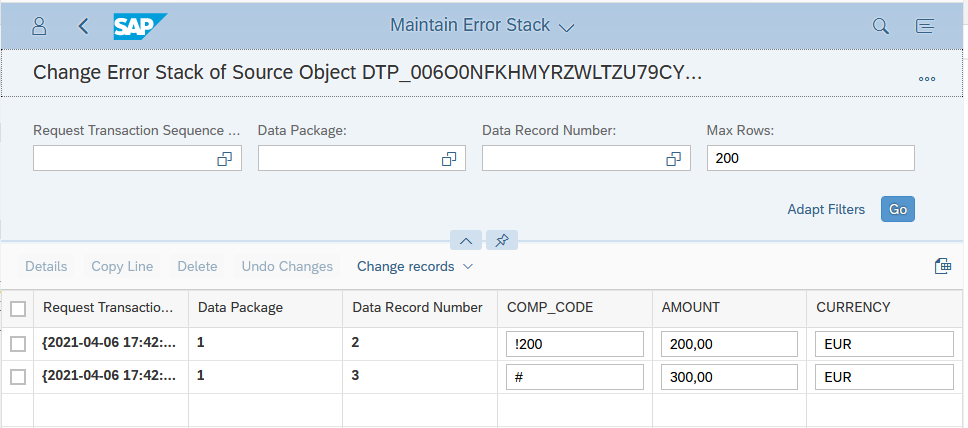
As the SQL Script routine is executed, the incorrect company codes are identified. Using the SQL__PROCEDURE__SOURCE__RECORD ID, these are written to the errorTab table with the corresponding error message.
As you can see from the screenshots, these are company codes !200 and #. Namely records 2 and 3.
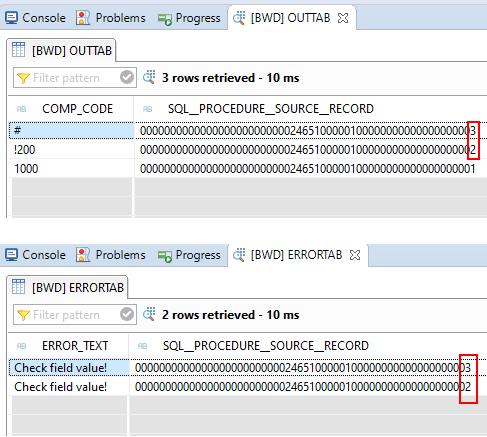
After the routine has been executed, these data records end up in the error stack.
Increase the performance of your BW with SQLScript

Depending on your requirements, you can extend this example to include additional fields to be checked. In practice, however, you do not need to check all fields. Experience shows that errors are more likely to occur in fields without a check table and in fields that are changed manually in the source. The table below provides an overview of the regular expressions you can use.
|
Expression |
Description |
|
a% |
Value starts with “a” |
|
%a |
Value ends with “a” |
|
%a% |
Value has "a" at any position |
|
_a% |
Value has “a” in the second position |
|
a_% |
Value starts with “a” and is at least two characters long |
|
a%z |
Value starts with “a” and ends with “z” |
|
[abc] |
“a”, “b” or “c” |
|
[a-z] |
Lowercase letters |
|
[A-Z] |
Capital letters |
|
[0-9] |
Digit |
|
. |
Any character |
|
[[:digit:]] |
Digits 0-9, corresponds to the expression [0-9] |
|
[[:lower:]] |
Lowercase letters, corresponds to the expression [a-z] |
|
[[:upper:]] |
Capital letters, corresponds to the expression [A-Z] |
|
[[:alpha:]] |
All letters, corresponds to the expressions [a-z] and [A-Z] as well as [[: lower:]] and [[: upper:]] |
|
[[:alnum:]] |
All capital and lowercase letters and all digits. Corresponds to the expressions [:alpha:] and [:digit:], i.e. [A-Z,a-z,0-9]. |
|
[[:punct:]] |
Punctuation marks, e.g.: . , " ' ? ! ; : # $ % & ( ) * + - / < > = @ [ ] \ ^ _ { } ~ |
|
[[:print:]] |
All printable characters, corresponds to the expressions [: alnum:], [: punct:] and SPACE |
|
[[:graph:]] |
All printable characters without SPACE, corresponds to the expressions [: alnum:] and [: punct:] |
|
[[:blank:]] |
Contains SPACE and TAB |
|
[[:space:]] |
Contains all whitespace characters: SPACE, TAB, CR, FF, NL, VT. |
|
[[:cntrl:]] |
Contains control characters: ACK CAN CR DC1 DC2 DC3 DC4 DEL DLE EM ENQ EOT ESC ETB EXT FF IS1 IS2 IS3 IS4 LF NAK NL NUL SI SO SOH STX SUB TAB VT |
|
[[:xdigit:]] |
Contains hexadecimal digits (0-9, A-F, a-f) |
|
[[=a=]] |
Contains equivalent characters. For example all letters based on "a". Like ä, à, â, á, etc. |
Are you planning to migrate to SQLScript and need help planning the right strategy? Or do you need experienced developers to implement your requirements? Please do not hesitate to contact us - we will be happy to assist you.

