






















An interesting measure to increase environmental sustainability in the field of AI is the use of resource-saving algorithms. In deep learning, a simple approach is to compare the number of parameters of two models to draw conclusions about an possible advantage in energy consumption. When comparing between classical machine learning methods, the statements about energy consumption are difficult to make due to the diversity of the algorithms’ operating principles. Here, a practical benchmark can help to get a feel for the energy efficiency.
In this article we will show you how to prepare and run a benchmark. Our results for different classification algorithms will help you to better estimate the energy consumption of the algorithms in the future.
Preparation of the benchmark
Basically, the energy consumption of the algorithms depends on a number of factors:
- the programming language used
- the implementation of the algorithm
- the chosen hyperparameters
- the hardware used
- the used database
When planning a benchmark, it is therefore necessary to consider which influencing factors should be kept constant and where even generalized statements should be possible.
The choice of the data basis also has an influence, since algorithms react with varying sensitivity to the amount of data and types of features. You can get a specific benchmark on your business case with a data extract of the corresponding use case. If you want to generalize here, multiple generic data sets can be used. For this purpose, the UCI Machine Learning Repository contains a large selection of datasets for supervised and unsupervised machine learning.
Preparation of the database
If purely the efficiency of the algorithms is to be measured, the data preparation for all algorithms should happen uniformly in advance. This includes, for example, converting categorical values, filling in missing values, and standardization. The number of features and the quantity of data points should be recorded as metadata for later standardization.
Preparing the algorithms
When selecting the learning algorithms, it should be decided which program library will be used and which hyperparameters will be set as configuration. Often the vanilla variant of an algorithm is sufficient here, if it concerns to compare the model types with one another. With ensemble methods however the number of the used models in the ensemble can have a strong influence on accuracy as well as the energy consumption. Similarly, the choice of the Support Vector Machines kernel is made through the hyperparameters and affects the execution time and thus the energy consumption.
Green AI - Sustainable Artificial Intelligence for corporations

Execution of the benchmark
In the execution of the benchmark, the prepared data and the instances of the algorithms are at hand. In order for the energy consumption to be recorded, various tools and libraries can be used. The tool CodeCarbon is particularly recommended here, since the reports are stored directly in an Excel table or are transmitted collectively via an API. The implementation is realized via a few lines of code. Separate collection for training and forecasting can help to assess the energy consumption of example scenarios according to the expected model usage and retraining frequency.
The following code snippet shows an example benchmark of multiple models over prepared data sets.
|
for dataset in datasets: X = dataset[“X”] y = dataset[“y”]
for model_name in models: # init tracker tracker_train = EmissionsTracker(tracking_mode="process", log_level="error", project_name=f'{dataset[“name”]},{model_name}', output_file="train.csv") tracker_pred = EmissionsTracker(tracking_mode="process", log_level="error", project_name=f'{dataset[“name”]},{model_name}', output_file="pred.csv") model = models[model_name] # tracker model training tracker_train.start() model.fit(X,y) emissions = tracker_train.stop() # tracker prediction tracker_pred.start() model.predict(X); emissions = tracker_pred.stop() |
Evaluation of the benchmark
When evaluating the benchmark, the results are visualized for communication in the project meeting or for use in model development. If different data sets are used, the energy consumption should be normalized by the number of features and the number of data points. Since the differences are of several orders of magnitude, the use of a logarithmic axis is recommended.
Depending on the statistical knowledge of the person involved, boxplots can give a quick overview of the variability of the energy consumption or simple bar charts can reduce the statements to the essentials.
In our benchmark of nine classification algorithms over six datasets with business context, the energy consumption of training and forecasting was captured.
In training, simple methods such as the K-Nearest Neighbor (KNN) method and Naive Bayes are very parsimonious. The ensemble methods Adaboost, Decision Tree Bagging and Random Forest are nevertheless more parsimonious than a neural network or the Support Vector Machines. The neural network with a hidden layer consumes on average 1390 x more energy than the KNN method. A look at the ranking is useful for the model selection.
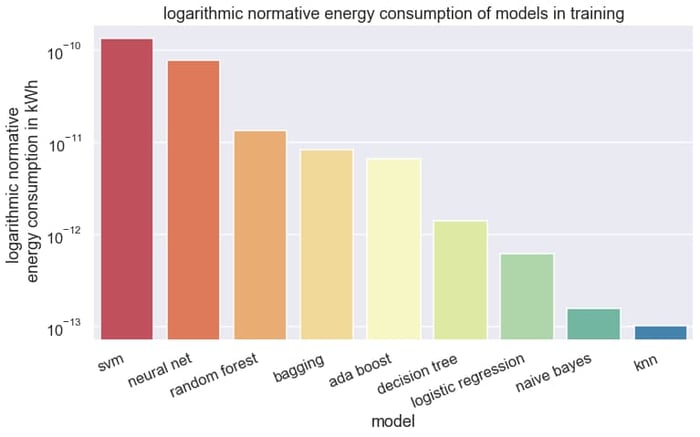
For enterprises, however, the use of the model is more critical. According to data from AWS and Azure, the application of the model, for example, in the form of a forecast, takes up around 90% of the total energy consumption. The KNN method, which only stores the data points in training, has almost the highest energy consumption in forecasting.
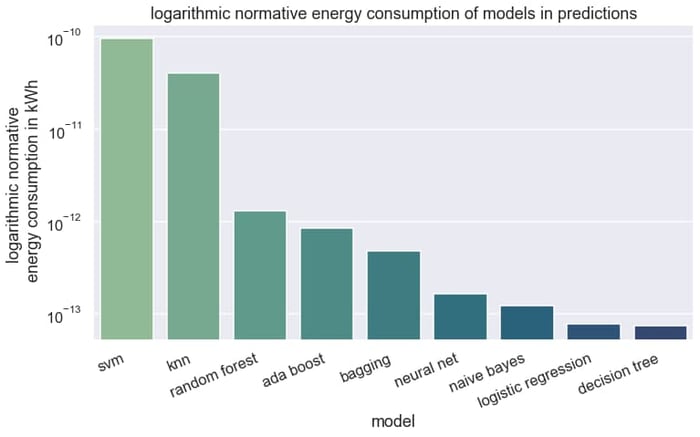
In summary, a benchmark on the energy consumption of models provides developers with a good tool for selecting models if the sustainability of AI applications is to be increased or the costs of model execution are to be reduced for economic reasons. When planning a benchmark, factors such as hardware, data preparation, and model configuration must be considered.
Do you have further questions about Green AI and the sustainable design of your data science area? We will be happy to advise you on possible steps and support you during implementation. Please contact us.

