/Logo%202023%20final%20dunkelgrau.png?width=221&height=97&name=Logo%202023%20final%20dunkelgrau.png)























In the earlier post "Two options for error handling with SAP BW and SQLScript" we looked in detail at the various error handling alternatives. We found out that the DTP error handling mechanism is only usable to a limited extent. Up to version BW/4HANA 2.0, this scenario is not usable at all, but even with BW/4HANA it can lead to performance problems.
That's why we'll look at a possible alternative in this article. In practice, the usual suspects are well known. It is always the same fields that contain incorrect data. Therefore, it makes sense to correct them directly in the routine so that the data records can be updated to the target.
Let's consider a simple example. In our SQLScript routine we check the COMP_CODE field (company code). For company codes that either contain control characters, start with an exclamation mark or are simply # (unassigned), not permitted characters are replaced with - (hyphen).
For this purpose we use the commands LIKE_REGEXPR and LIKE in conjunction with CASE WHEN. With CASE WHEN you can further differentiate the handling of the incorrect data. For example, you can replace exclamation marks with a hyphen and fill all unassigned (#) company codes with a dummy company code.
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY.
outTab =
SELECT
CASE
WHEN comp_code LIKE_REGEXPR '.*[[cntrl]].*' THEN REPLACE (comp_code, '.*[[cntrl]].*', '-')
WHEN comp_code LIKE '!%' THEN REPLACE (comp_code, '!', '-')
WHEN comp_code = '#' THEN REPLACE (comp_code, '#', '-')
ELSE comp_code
END AS comp_code,
currency, '' as recordmode, amount, record, SQL__PROCEDURE__SOURCE__RECORD
FROM :inTab;
errorTab= SELECT * FROM :errorTab;
ENDMETHOD.
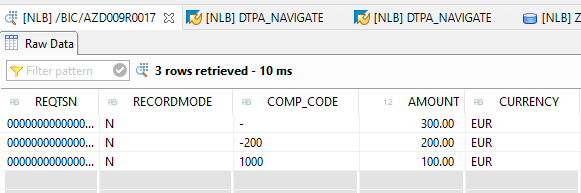
The result is shown in the next picture. You can see the source records in the INTAB table. The corrected counterparts are in table OUTTAB.
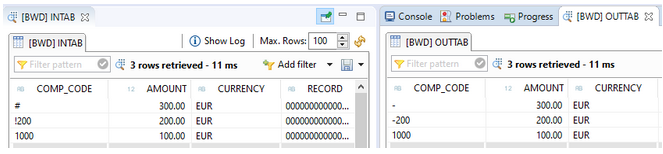
With this approach, data can be successfully posted to an ADSO.
Increase the performance of your BW with SQLScript

A list of regular expressions that will help you find the incorrect records can be found in the table below.
|
Expression |
Description |
|
a% |
Value starts with “a” |
|
%a |
Value ends with “a” |
|
%a% |
Value has "a" at any position |
|
_a% |
Value has “a” in the second position |
|
a_% |
Value starts with “a” and is at least two characters long |
|
a%z |
Value starts with “a” and ends with “z” |
|
[abc] |
“a”, “b” or “c” |
|
[a-z] |
Lowercase letters |
|
[A-Z] |
Capital letters |
|
[0-9] |
Digit |
|
. |
Any character |
|
[[:digit:]] |
Digits 0-9, corresponds to the expression [0-9] |
|
[[:lower:]] |
Lowercase letters, corresponds to the expression [a-z] |
|
[[:upper:]] |
Capital letters, corresponds to the expression [A-Z] |
|
[[:alpha:]] |
All letters, corresponds to the expressions [a-z] and [A-Z] as well as [[: lower:]] and [[: upper:]] |
|
[[:alnum:]] |
All capital and lowercase letters and all digits. Corresponds to the expressions [:alpha:] and [:digit:], i.e. [A-Z,a-z,0-9]. |
|
[[:punct:]] |
Punctuation marks, e.g.: . , " ' ? ! ; : # $ % & ( ) * + - / < > = @ [ ] \ ^ _ { } ~ |
|
[[:print:]] |
All printable characters, corresponds to the expressions [: alnum:], [: punct:] and SPACE |
|
[[:graph:]] |
All printable characters without SPACE, corresponds to the expressions [: alnum:] and [: punct:] |
|
[[:blank:]] |
Contains SPACE and TAB |
|
[[:space:]] |
Contains all whitespace characters: SPACE, TAB, CR, FF, NL, VT. |
|
[[:cntrl:]] |
Contains control characters: ACK CAN CR DC1 DC2 DC3 DC4 DEL DLE EM ENQ EOT ESC ETB EXT FF IS1 IS2 IS3 IS4 LF NAK NL NUL SI SO SOH STX SUB TAB VT |
|
[[:xdigit:]] |
Contains hexadecimal digits (0-9, A-F, a-f) |
|
[[=a=]] |
Contains equivalent characters. For example all letters based on "a". Like ä, à, â, á, etc. |
Are you planning to migrate to SQLScript and need help in planning the right strategy? Or do you need experienced developers to implement your requirements? Please do not hesitate to contact us - we will be happy to advise you.

