






















In the modern business landscape of data driven decision making, factors that help you build a robust and adaptable infrastructure for your data processing are key. Apache Airflow is a powerful tool for managing complex data workflows, crucial for any organization looking to harness the power of their data effectively.
The core structural elements of Apache Airflow are Directed Acyclic Graphs (DAGs). These DAGs serve as the framework within which tasks are defined, organized, and executed. Each DAG represents a collection of tasks, where each task is a unit of work, and the relationships between these tasks are defined by their dependencies and execution order. This structure ensures that tasks are executed in a way that respects their interdependencies, without creating circular dependencies that could lead to execution failures or infinite loops. Airflow guarantees that the execution of all intermediate steps of data processing are documented and errors, should they arise, can be automatically handled or identified for further inspection easily.
The nature of this framework and its application through Python code allows for great flexibility by itself, which is a key advantage of Airflow compared to many low-code/no-code orchestration platforms. This adaptability can be further leveraged by utilizing parametrization, both on DAG and task level, which will be the topic of today.
In short, Airflow parameters allow us to provide runtime configuration to the tasks we’re executing, either through the Airflow graphical user interface (GUI) or by adding these parameters to our CLI-calls.
DAG level parameters
We can add parameters to a DAG by initializing said DAG with the “params” keyword. The values themselves are set in the form of a Python dictionary object containing the names and either a default value or a Param class object. The latter has the advantage of allowing us to specify the data type of the parameter value, as well as setting some additional attributes to define how users interact with it. For example we could set an additional description, upper or lower bounds for numeric values, minimum or maximum lengths for string values or an enum containing the allowed values.
The Param definition makes use of the [JSON-Schema](https://json-schema.org/draft/2020-12/json-schema-validation), which means that we are able to use all of the validation keywords for example.
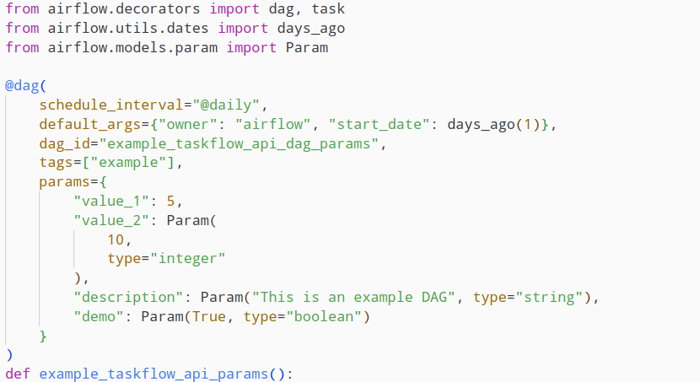 DAG initialization with configured parameters
DAG initialization with configured parameters
Task level parameters
It is also possible to add parameters to individual tasks. The values set here have higher priority than DAG-level default parameter values, but lower priority than user-supplied parameters that are set when triggering the DAG.
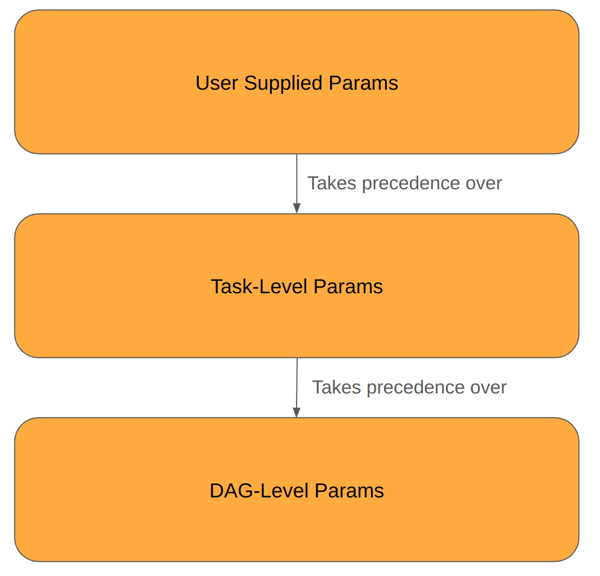 Order of precedence of parameters set at different levels
Order of precedence of parameters set at different levels
Optimize your workflow management
with Apache Airflow!

Working with params
There are multiple ways to access these parameters. The most straightforward way is injecting and unpacking the “context” or “kwargs” keyword argument in the task and then accessing the parameter values this way.

 Accessing params via context injection
Accessing params via context injection
Another way is using the params as a Jinja template, using the syntax for [templated strings](https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html#templates-ref)

The Trigger UI Form
Introduced in Airflow version 2.6.0, the Trigger UI Form allows users to customize the runtime arguments via a comprehensive page in the Web UI when manually executing a DAG, by clicking the “Trigger DAG w/ config” button (previous to version 2.9.0) or the “Trigger DAG” button (version 2.9.0) respectively . This feature will read the preconfigured parameters set on DAG level and provide us with input masks for the respective fields. These fields already take into account the data type of the specific parameters, which makes their usage more comfortable and less prone to errors. In order for that button to appear even when no parameters are configured for the specific DAG, the environment variable “AIRFLOW__WEBSERVER__SHOW_TRIGGER_FORM_IF_NO_PARAMS” has to be set to “True”.
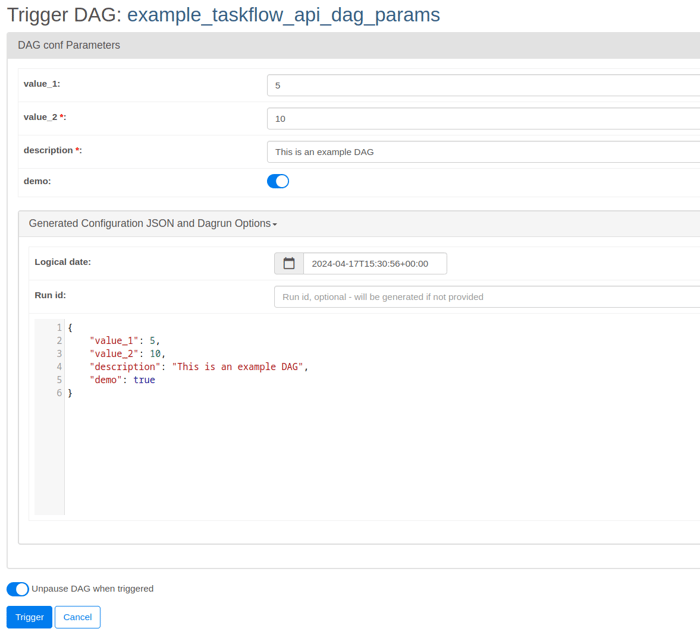 Airflow Trigger UI Form
Airflow Trigger UI Form
Benefits of parametrizing DAG runs
Now that we have explored how we can configure our DAGs to incorporate Airflow parameters, you might wonder, what some real world applications for this functionality might be.
One potential use case might arise when your DAG is processing data within a certain time window, which you could configure using these parameters by dynamically setting a start/end date, instead of relying on the default values you might have configured for the scheduled DAG runs.
Another example might be creating a DAG for administrative tasks within your IT ecosystem, like creating users and assigning permissions for certain applications. The application of these parameters could allow you to set the user details manually, like their username or role on the target system as parameters and then execute the DAG to create this configuration. Those are just some examples that scratch the surface of what is possible by incorporating parametrization into the design of your data pipelines.
Optimizing your data pipelines - Our Conclusion
In the ever changing landscape of business data needs, Apache Airflow has proven to keep up to the challenge of continuous evolution to satisfy customer needs. The topic of parametrizing your DAGs is just one of the many facets that allow you to customize the platform to your specific needs. If you are curious as to how to tailor Airflow to fit your business requirements or our other areas of expertise, feel free to contact us at any time!

