






















Before a machine learning model can provide continuous business value, it must first overcome the obstacle of practical implementation. In addition to prediction, other parts of the machine learning workflow, from data preparation to deployment of the trained model, should also be automated to keep the model always up-to-date.Many options are available from a technical perspective for the workflow management, i.e., the administration, scheduling and execution of tasks in the workflow. In addition to the widespread cronjobs, the workflow management platform Apache Airflow is also very popular. In this article, we explain how Airflow optimally meets the challenges of machine learning workflows and present an architecture variant for small machine learning (ML) teams.
Apache Airflow
In Airflow, workflows are defined, scheduled and executed as Python scripts. Dependencies between tasks and thus complex workflows can be mapped quickly and efficiently. The feature-rich web interface provides a good overview of the status of workflow runs and speeds up troubleshooting immensely. The framework is also open-source and free to use.
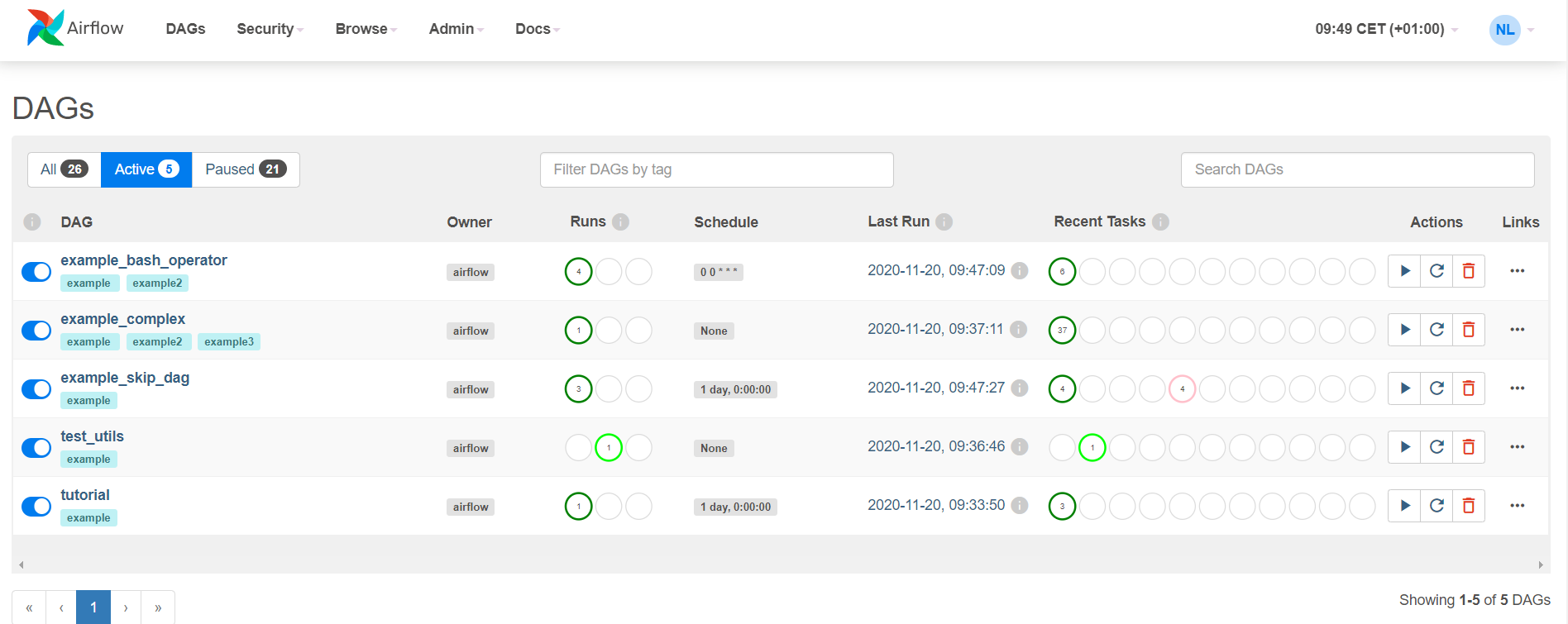
Apache Airflow web interface. The status of the workflow runs is visible on the left ( Runs). The status of the tasks of the last workflow is visible on the right (Recent Tasks).
Airflow performs the following tasks for machine learning workflows:
- Define, execute, and monitor workflows
- Orchestrate third-party systems to execute tasks
- Provide a web interface for excellent visibility and comprehensive management capabilities
If you would like to learn more about the underlying concepts and components of Apache Airflow, we recommend reading our whitepaper "Effective Workflow Management with Apache Airflow 2.0". There, the basic ideas are explained in detail and you will get practical application ideas regarding the new features in the major release.
Optimize your workflow management
with Apache Airflow

Why is Airflow particularly suitable for Machine Learning?
Machine learning workflows are usually more complex than ETL workflows due to the dependencies between the individual steps and the large number of data sources involved. In addition, the different models often have different hardware requirements (CPU vs. GPU). Therefore, simply starting the workflows with cron jobs often reaches its limits and is prone to errors due to the lack of dependencies between the individual tasks. Because of its ease of use and implementation, Apache Airflow is becoming widely accepted for workflow management of machine learning applications.
Machine Learning Workflows in Airflow
A machine learning workflow includes various task packages that are divided into data preparation, model training and evaluation, and model deployment. Airflow is responsible for the execution of the individual workflow runs. Depending on your needs, you can create a workflow with integrated steps (see figure) or you can define separate workflows for the subtasks, if individual components (e.g. data preparation) should follow their own time interval.

Simple machine learning workflow with integrated steps
- Data preparation
In the course of preparation for training, various ETL processes take place. Within the workflow, important information about the data scope and the statistical properties of the features can be generated. These help to uncover potential sources of error. - Model training and evaluation
In order for the model to be able to adapt to a new data situation, regular training on current data is recommended. This can be started chronologically or via REST API if the productive model reaches a certain error barrier. - Deployment of the model
Depending on whether the model is used as a service within an application or is used as a generator of forecast tables, the deployment differs. If the model is to provide forecasts on a regular basis, even the forecast step can be scheduled from Airflow.
Machine Learning-architecture for the entry
The Airflow installation is flexibly configurable and allows scaling according to requirements. This is primarily implemented by selecting the appropriate execututer. An entry-level architecture is explained below. This meets the requirements of small teams that want to run workflows on a single server. In addition to Airflow, Git for version control and Anaconda for isolation play a role. For a fast, secure connection to SAP HANA, for example, the NextLytics Software Development Kit (NLY-SDK) can be used, which we would be happy to present to you in more detail upon request.

ML architecture with Airflow (scheduling), Git (version control), Anaconda (isolation) and an Airflow DAG for deployment and connection to databases and file systems
- Single-node architecture Airflow
The individual tasks of the workflow are executed locally on the system on which Airflow is installed. Here a parallel execution of the tasks is given by the LocalExecuter. There are several worker instances of the web server. Since Airflow 2.0 it is also possible to use multiple scheduler instances.
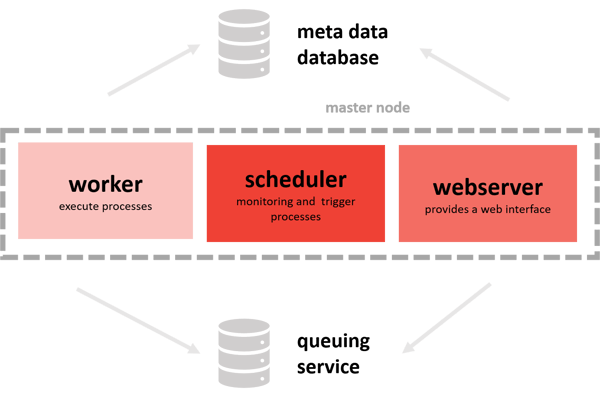
In the single node architecture the tasks are executed per worker, the web server and the scheduler on the server.
- Anaconda Environments
If the machine learning workflows are executed locally on a server, the architecture must provide a way to implement the different software-side requirements of the models. This is a particularly important point in machine learning applications, since specific versions of the individual program libraries are often required. Virtual environments are suitable for this purpose. Conda environments are often used here. The scripts are then executed via the interpreter of the desired environment. - Data exchange
Airflow is conceptually not designed for "real" data pipelines. The generated data must be stored between the steps. This can be done on the server, in a database or in the cloud, for example. Airflow offers with XCOM a communication possibility between the different tasks. This can be easily defined via the TaskflowAPI. - Deployment of the workflow files
The workflows are designed in the form of Python files. When a workflow is ready for production, it is stored in a Git repository. From there, it is transferred to the server via pull request. In this case, the periodical pull request is controlled via a separate Airflow DAG. An improvement of the continuous deployment with e.g. upstream automated tests can be realized with Jenkins, Drone or GitHub Actions.
Of course, the architecture presented is not suitable for all application scenarios. If the number of workflows increases rapidly, the architecture can no longer handle the requirements. Fortunately, Airflow can be scaled efficiently with Kubernetes, Mesos or Dask. But operating on distributed systems should be carefully planned.
We are happy to support you as your competent project partner for your end-to-end machine learning projects and/or to evaluate your status quo. We help you to realize robust and scalable machine learning workflows on Apache Airflow. Contact us at any time!

