






















Getting started with the workflow management platform Apache Airflow is easy. Workflows are defined, scheduled and executed with simple Python scripts. The provided web interface informs the user at any time about the status of the workflow run and accelerates troubleshooting immensely. The extensive functionality also convinces users in thousands of companies.
Easy to learn - difficult to master: Especially in the initial phase, there is a risk of overlooking some pitfalls. However, these are avoidable. We at NextLytics would therefore like to share with you our Apache Airflow Best Practices for workflow management.
| This article assumes knowledge of the basic structure of Airflow. If the terms scheduler, operator and DAG don't mean anything to you, please read on here or take a look at our whitepaper on Apache Airflow 2.0. |
- Consider maintenance
Sooner or later, there comes a moment when a workflow is temporarily unavailable to run. For example, during a system change or maintenance, the data source is temporarily unavailable. The workflow can easily be paused via the web interface or the CLI. Re-entry is usually somewhat problematic. By default, missed runs are caught up, which can lead to an overload of the system. If the workflow-runs are not to be repeated, it is recommended to use the parameter catchup=False in the workflow configuration and to use the LatestOnlyOperator as workflow entry point to execute only the latest run.
- Keep your workflow files up to date
Versioning and deploying program code is a recurring theme in IT. Since the workflows in Airflow itself are generated with Python code, a way must also be found to keep them up-to-date. In practice, the simplest way is to synchronize with a Git repository. Airflow loads the files from the dags folder in the Airflow directory. There, a subfolder can be created that is linked to the Git repo. The synchronization itself can be realized via a workflow with a BashOperator and the corresponding pull request. Other files that are used within a workflow (in the machine learning area, for example, the training script) can also be synchronized via a Git repository. The pull request can take place at the beginning of the workflow.
- Move the data processing to separate scripts
A workflow is created in the Python file using a DAG object. Various tasks are assigned to these and their dependencies on each other are defined. The actual work then takes place within the tasks during execution. Very often, however, essential steps of data processing are created in the DAG file, which is actually only supposed to define the workflow. This is problematic because the file must be readable within seconds. The workflow file is evaluated in very short intervals in order to be able to transfer the changes directly.
Thus, in an attempt to keep the file lean, the use of modules is recommended. The imported functions can be accessed using PythonOperator. Since Airflow 2.0, a simplified creation of workflows via TaskflowAPI is possible.
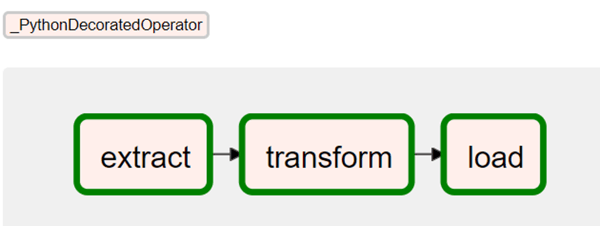 The TaskFlow API makes it easy to define new workflows as a series of Python functions
The TaskFlow API makes it easy to define new workflows as a series of Python functions
- Use variables for more flexibility
In Airflow, there are many ways to make the DAG objects more flexible. During runtime, context variables are passed to each workflow run. These include the run ID, the execution date, and the times of the last and next run. These are quickly integrated into an SQL statement. For example, the data period can be adjusted to the set execution interval. Airflow offers an additional possibility to store variables in the metadata database. These are customizable via the web interface, the API and the CLI. This can be used, for example, to keep a file path flexible.
Practical tip: A separate connection is required for each call of a variable from the metadata database. So that the connection number is not blown up, it is recommended to save related variables as JSON objects.
Optimize your workflow management
with Apache Airflow

- Keep an eye on the time
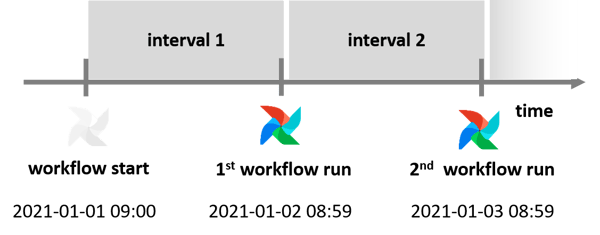
Time plays the main role in Airflow. The execution of all workflows is precisely timed. Ironically, the time concept causes confusion at several points. For example, the execution time (execution_time) does not correspond to the real runtime. Rather, execution time denotes the start timestamp of its planning period. The real runtime is not until the end of the period.
For instance, if the first run is scheduled on 2021-01-01 at 09:00 and is to be repeated every 24h, the first runtime is on 2021-01-02 at 08:59. This shift can be problematic if the execution time is used incorrectly as a context variable in an SQL statement. In the long run, there will be an option in Apache Airflow to switch between execution at the beginning and end of an interval.
 Practical tip: If the mental conversion of the UTC time from the web interface becomes too exhausting in the long run, since Airflow 1.10.10 there is the possibility to set the user-specific time zone in the web interface.
Practical tip: If the mental conversion of the UTC time from the web interface becomes too exhausting in the long run, since Airflow 1.10.10 there is the possibility to set the user-specific time zone in the web interface.
- Set priorities
As soon as several workflows fight for execution at the same time, temporary bottlenecks occur. Which workflow is preferred here can be controlled with thepriority_weight parameter. The parameter is set per individual tasks or can be passed as a default argument for the entire DAG. The latency time when starting a workflow can also be reduced via multiple scheduler instances since Airflow 2.0.
- Define Service Level Agreements (SLA)
In Airflow, a time can be defined in which a task or the entire workflow must be successfully completed. If this time limit is exceeded, the responsible persons are informed and the event is recorded in the database. On this basis, it is possible to search for anomalies that have led to the delay. For example, there may be an unusually high amount of data.
Not enough yet? We have summarized further practical tips for the use of Apache Airflow in our whitepaper. We will also be happy to help you personally with individual questions on the best possible design of your workflow management. Contact us and benefit from the extensive practical experience of our consultants.

