






















Artificial intelligence (AI) and machine learning (ML) projects are becoming increasingly attractive in national and international companies. However, the effort involved often is underestimated, while the outcomes achieved by a project of this kind could be overestimated because of unrealistic expectations. In the worst case, the feasibility of an ML model cannot be sufficiently proven by a prototype (see ML workflow). However, if you think that the expenses and work done so far would have been useless, you are mistaken. In this article, we will show you the advantages of machine learning projects and why it is worthwhile - apart from the actual project goal - to start an AI project in your company.
Increased data quality
An ML model can only be as good as the underlying data it uses. There is a reason why a common saying is "garbage in, garbage out". That means that a primary goal of an ML project is to increase the quality of the data. That includes the amount of data to be acquired as well as the processing.
During data acquisition, appealing interfaces become visible, and already existing data structures are recognized and analyzed in more detail. For integration, multiple data sources should get considered. The amount and relevance of data needed depending on the ML project and the guiding question. For example, in the case of time-based prediction, it should be ensured that current, continuous data with a concrete timestamp are available. Typical sources of error should be detected and eliminated at an early stage by checking for plausibility, form, and correctness during data collection.
Once sufficient data is available for the project, the next step is to process the data. A data scientist spends most of his or her time on data preprocessing and data cleansing. For example, missing values need to be either filtered or replaced with suitable values (e.g., imputed). Also, a uniform data format should get ensured to process the data appropriately. The following example shows how data preprocessing and cleaning could be used to correct the data and thus increase the data quality. Here, the focus was on customer data so that those rows were filtered or removed that could not be assigned a unique customer ID. Missing values for the "Revenue" column, on the other hand, were replaced with zeros in consultation with the business department. In addition, the uniform name "USA" was introduced, to better summarize and analyze the customers of this region.
 Example of data preprocessing and data cleansing
Example of data preprocessing and data cleansing
Once a uniform approach to data processing is established, it is also possible to implement a reusable, generic preprocessing pipeline. That helps the company to standardize data processing for a wide variety of projects. That means, besides the actual use of the data in an ML model, the data is ready for any other analysis. In summary, cleansed data ensures that companies can work with the data with a higher level of reliability, allowing them to make informed decisions.
Advance your business through Artificial Intelligence and Machine Learning

Data Discovery
Now that the data has reached a certain quality, it can go through the first analysis. Usually, this takes place in the course of a visual EDA (exploratory data analysis). Various plots and statistical tests help quantifiably confirming or refute different assumptions about the data in this phase. This step is called Data Discovery, as one gets first exciting and partly unknown insights into the data.
In this process, technical anomalies are translated into business insights, and patterns, trends, and outliers are crystallized. That makes it possible for cross-team employees from other disciplines to get an overview of the data without in-depth understanding.Our example shows through a simple bar chart that the US is the largest market.
In this step, further interesting questions for follow-up projects could get developed based on specific key figures. That could help to increase the efficiency and productivity of a company. Data Discovery serves as a basis for decision-making, as the strength of an impact can be more easily assessed.
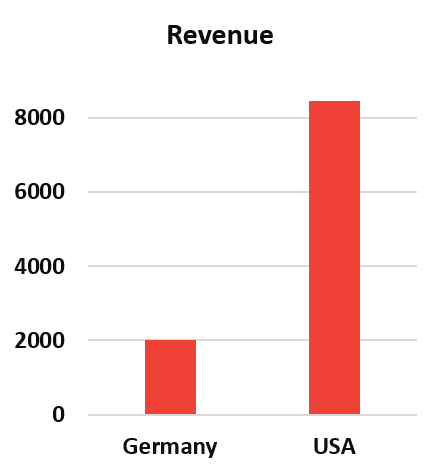 Example image for Data Discovery
Example image for Data Discovery
Developing processes and structures of a digital team
Apart from how an AI project turns out, it helps to strengthen, improve and possibly even build a digital data team in the company. The latter is especially interesting and important for those departments that have worked little with Big Data and/or are developing their first ML model. The professional skills of a data scientist, data engineer, and machine learning engineer will be learned and mended. In our blog article next week, we will briefly summarize the core competencies of each role.
To enable cross-disciplinary collaboration, good documentation of the individual development steps is necessary. That sustainably strengthens understanding and traceability for the entire team and beyond. That also includes aspects such as plausible and helpful code commenting as well as clean coding itself. To not lose overview, we recommend agile project management, just because of the unpredictability of an ML project and the iterative approach. It helps that tasks and subsequent steps are communicated and organized.
Nowadays, agile software development methods are used and established in such projects. Usage of CI/CD tools can hardly be avoided and is part of everyday life for colleagues from the digital environment. CI/CD stands for Continuous Integration and Continuous Delivery or Deployment and helps to optimize digital processes. Frequently used tools in this context include Jenkins and Github. An established CI/CD pipeline helps the company achieve optimal technical positioning and shorten decision-making paths.
Advantages of machine learning - Our Conclusion
The advantages of implementing and establishing a machine learning model in the company can be summarized quickly: Early identification of patterns and trends, detection of specific influencing variables, and the possibility of process optimization. That replaces manual work, automates repetitive tasks, and thus increases productivity.
The insights and experience that such a project produces are highly significant in our fast-paced digital world. Even the first step of data sourcing provides feedback on the data structure and enables increasing data quality besides data processing/cleansing.
Data discovery gets the ball rolling and opens the doors for further projects. Knowing what information can be derived from the data helps considerably. And while the overall goal should be kept in mind, it is worthwhile to pursue intermediate goals and celebrate secondary successes - such as getting to know a new innovative tool.
If you need support in the planning and realization of machine learning projects, please do not hesitate to contact us. Our consultants have different areas of expertise and complement your machine learning team with the desired competencies.

